Update:
2020-09-27 09:50 PM -0400
TIL
Romabama rules
- a transcription-transliteration system
for BEPS (Burmese-English-Pali-Sanskrit)
languages:
name changed from Introduction to Romabama on 2020July01
RBM-rule2.htm
by U Kyaw Tun, M.S. (I.P.S.T., U.S.A.),
Daw Khin Wutyi, B.Sc., and staff of Tun
Institute of Learning (TIL). Not for
sale. No copyright. Free for
everyone. Prepared for students and
staff of TIL Research Station,
Yangon, MYANMAR :
http://www.tuninst.net ,
www.romabama.blogspot.com
index.htm |
Top
RBM-rules-indx.htm
Rule 02
: Vowels
 {þa.ra.} - spelled with Old English "Thorn Letter"
{þa.ra.} - spelled with Old English "Thorn Letter"
 {þa.} with Thibilant sound
{þa.} with Thibilant sound
• Vowels in speech (Close or High,
Mid, Central, Open or Low)
• Types of Vowels : Inherent vowel
 {mwé-hkän þa.ra.} of the Akshara, and Nuclear vowel
{mwé-hkän þa.ra.} of the Akshara, and Nuclear vowel
 {Ñu-ka.li þa.ra.} of the syllable
{Ñu-ka.li þa.ra.} of the syllable
• Arrangement of letters of English alphabet : once you have Alef (ox) you need
to protect it Bet (shed, house)
• Extension of 26 letters of English alphabet
:
Differentiation of Capital and Small letters
• Sinhala script : used for writing Pali language
in SriLanka
UKT notes
• Writing systems or scripts
1. Abjad - consonants are more important than vowels, mny nn-Smtc lnggs sch `s `nglsh cn b wrttn wtht vwls `nd rd wth lttl
dffclty".
2. Abugida (Akshara
 {ak-hka.ra} - Syllable system ) ,
{ak-hka.ra} - Syllable system ) ,
3. Alphabet (Alphabet - Letter system),
4. Syllabary ,
5. Logogram ,
6.
Proto-Writing
7. Unknown ,
8. Ideographic
Contents of this page
Romabama Rule 02 Vowels
{þa.ra.} - spelled with Old English "Thorn Letter"
UKT 180403, 200806: In dealing with Bur-Myan vowels,
we have to think of the acoustic vowels first.
The next step is consider how the glyph is written.
A disturbing difference between Bur-Myan and Skt-Dev
(& Engl-Lat) is how to write a word such as
 {ké} के . For comparison take a southern Indic script like Telugu
கெ . Be sure to
consider the problem before rendering by the computer program.
{ké} के . For comparison take a southern Indic script like Telugu
கெ . Be sure to
consider the problem before rendering by the computer program.
In Bur-Myan
and Telugu, the vowel (sign) is placed before the consonant (letter). In Engl-Latin
and Skt-Dev, it is the reverse: the vowel (sign) is placed after the
consonant (letter). Please note that Bur-Myan does not have a reliable font
until the time Unicode is adopted, and so I'm relying on my Romabama system.
Bur-Myan:
 +
+
 -->
-->
Telugu: க + ெ --> கெ
Engl-Lat: k + e --> ke
Skt-Dev: क + े --> के
 Representing vowels of BEPS is quite
difficult because, first, both Bur-Myan
and Skt-Dev has two sets of glyphs to
represent the same vowel sound: vow-let
(vowel letters) & vow-sign
(vowel signs), whereas Eng-Lat has
only one set.
Representing vowels of BEPS is quite
difficult because, first, both Bur-Myan
and Skt-Dev has two sets of glyphs to
represent the same vowel sound: vow-let
(vowel letters) & vow-sign
(vowel signs), whereas Eng-Lat has
only one set.
I had not consider why it was necessary for Devanagari script and Myanmar script
of the Akshara-Syllable system to have two sets of vowels in script. The Latin
script (of English-Latin) of the Alphabet-Letter has the need of only one set of
vowels. This question is also related to the differentiation of
 {þa.wûn} and
{þa.wûn} and
 {a.þa.wûn}
vowels in the Akshara-Syllable.
{a.þa.wûn}
vowels in the Akshara-Syllable.
 It is also probably related to the Cardinal
vowels of
Daniel Jones. I've opened a new file this topic in RBM-Rule 5 -
Romabamar-rule5.htm (link chk 200821)
It is also probably related to the Cardinal
vowels of
Daniel Jones. I've opened a new file this topic in RBM-Rule 5 -
Romabamar-rule5.htm (link chk 200821)
UKT 200821: A short paper on Cardinal vowels by J Coleman is in TIL
HD-PDF and SD-PDF libraries:
-
JColeman-CardinalVowels<Ô> /
Bkp<Ô>
(link chki 200821)
Second, Eng-Lat has no way of differentiating a short vowel such as
 {a.} or {aa.} from its allophone the long vowel
{a.} or {aa.} from its allophone the long vowel
 {a} or {aa}. The difference between
the two is the length of pronouncing
the vowel sound measured in eye-blinks:
one eye-blink for a short vowel and two
for a long vowel. Note that terms like "short vowel", "long vowel", and
"allophones" are for English speakers. I got into a mess when I use them
indiscriminately. Now, I use matra or eye-blinks.
{a} or {aa}. The difference between
the two is the length of pronouncing
the vowel sound measured in eye-blinks:
one eye-blink for a short vowel and two
for a long vowel. Note that terms like "short vowel", "long vowel", and
"allophones" are for English speakers. I got into a mess when I use them
indiscriminately. Now, I use matra or eye-blinks.
 In comparing Bur-Myan vowels to IPA,
we usually rely on two-dimensional diagrams:
In comparing Bur-Myan vowels to IPA,
we usually rely on two-dimensional diagrams:
1. the vowel quadrilateral of Daniel Jones
2. the tongue positions shown sideways - as front vs back, and close (or
up) vs open (or down).
There is also a mid-central vowel, known as Schwa with IPA
symbol /ə/. The word Schwa /ʃvɑː/ is German derived from Hebrew, which I've
transcribed as
 {shwa.} -->
{shwa.} -->
 {þwa.}. See downloaded paper on Schwa in TIL HD-PDF and SD-PDF libraries: -
GMarkova-Schwa<Ô> /
Bkp<Ô> (link chk
200927
{þwa.}. See downloaded paper on Schwa in TIL HD-PDF and SD-PDF libraries: -
GMarkova-Schwa<Ô> /
Bkp<Ô> (link chk
200927
3. the vowel-space - the space in mouth in which the tongue can move
4. sometimes on the lip openings.
However, these diagrams lead us to forget
that pronouncing the vowels depend on the
idiolect (person to person), the dialect
(group of persons), the language,
particularly the first language, L1
(living languages such as Burmese, English,
Hindi, Mon, etc.), and the language group
(such as IE (Indo-European), Tib-Bur
(Tibeto-Burman), Aus-Asi (Austro-Asiatic).

 We must also not forget that how a person
articulate can be judged differently by
foreign phoneticians - who, in the 19th century, were English, French, German
and Russian with differing L1s.
We must also not forget that how a person
articulate can be judged differently by
foreign phoneticians - who, in the 19th century, were English, French, German
and Russian with differing L1s.
We have to emphasize that there are overlap
of the "same" vowel, say /i/, even
in the same linguistic group. Thus in IE group,
we find the Danish speakers, and the English
speakers pronouncing the same vowel slightly
differently. We should expect more differences
when we compare the vowels of different linguistic
groups, say those of English (belonging to IE),
and Burmese (belonging to Tib-Bur).
However, this last
piece of uncertainty can now be taken
care of by measuring the acoustic signals,
the so-called formants F1 and F2 and giving
a statistical model in three-dimensions as
shown below.
I have to adopt a three-dimensional vowel
diagrams to include the Skt-Dev vowels.
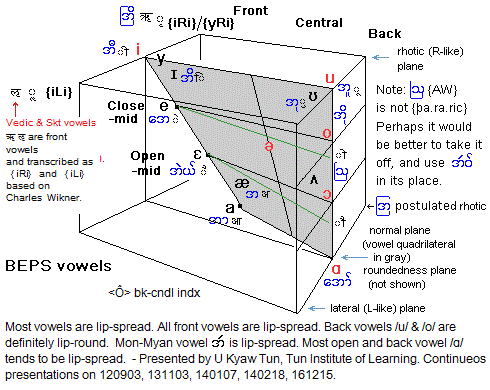

Contents of this page
1. Inherent vowel of the Consonantal-Akshara

2. Nuclear vowel of the Word-Syllable
3. Cardinal vowel, clearly illustrated in Bur-Myan and Pali-Myan vowels
given by A.W. Lonsdale.
The 8 Pali-Myan Vowel-Letters are made up of three
{þa.wûn}-pairs:
/a/ -
{A.} अ,
{A} आ ;

/i/ -
 {I.} इ,
{I.} इ,
 {I} ई ;
{I} ई ;
/u/ -
 {U.} उ ,
{U.} उ ,
 {U} ऊ ;
{U} ऊ ;
and one
{a.þa.wûn}-pair:
/é/ -
 {É.} ए ,
{É.} ए ,
/o, c, ɒ/ -
 {AU}/
{AU}/
 {EAU} ओ
{EAU} ओ
UKT 200823: /o, c, ɒ/ are so near to each other that most phoneticians could not
distinguish them. The only method that is available at present is to study their
Formants.
See:
https://en.wikipedia.org/wiki/Formant 200823
English or Engl-Latin of the Alphabet-Letter system has only one type of vowel due to the canonical structure of its
syllable

 {sa.ka:þän-su.}, CVC, and also due to the nature of
the Latin alphabet, where
the smallest syllabic unit is the mute Letter
{sa.ka:þän-su.}, CVC, and also due to the nature of
the Latin alphabet, where
the smallest syllabic unit is the mute Letter

 {þän-mè.sa-loän:}, C. Both onset-consonant and
coda-consonant are mute Letters. The Eng-Latin syllable owes its
pronunciation to its Nuclear vowel
{þän-mè.sa-loän:}, C. Both onset-consonant and
coda-consonant are mute Letters. The Eng-Latin syllable owes its
pronunciation to its Nuclear vowel
 {Ñu-k~li þa.ra.}, V.
{Ñu-k~li þa.ra.}, V.

Bur-Myan, Pali-Myan and Skt-Dev of the Akshara-Syllable system, has two types of vowels:
Inherent vowel
{mwé-hkän þa.ra.} and Nuclear vowel
{Ñu-k~li þa.ra.}.
Each Bur-Myan consonant is pronounceable, and is considered to be
"living" and as such is a syllable. Thus,
{ka.} and
 {ta.} are living consonants or syllables, because each has
{mwé-hkän þa.ra.}
{a.}.
{ta.} are living consonants or syllables, because each has
{mwé-hkän þa.ra.}
{a.}.
Every Bur-Myan consonant has "life" - the same inherent vowel
{a.} - which is not true in Mon-Myan. Mon-Myan has two kinds of inherent vowels
{a.} and
 {é}.
{é}.
The living consonant, C, with its inherent vowel
{a.}, is syllabic. It can be "killed" by a Virama
 {a.þût} (lit. "a vowel-killer) when it loses its ability to be pronounced
because it has been "killed". It has become mute, and is denoted by Ç .
{a.þût} (lit. "a vowel-killer) when it loses its ability to be pronounced
because it has been "killed". It has become mute, and is denoted by Ç .
Bur-Myan and Skt-Dev words
 {waad} and syllables
{sa.ka:þän-su.} have the canonical structure CVÇ . Thus:
{waad} and syllables
{sa.ka:þän-su.} have the canonical structure CVÇ . Thus:
{ka.} क (syllabic) + viram
{a.þût} -->
 {k} क् (mute)
{k} क् (mute)
{k} क् (mute) +
{a.} (life-giver) -->
{ka.} क (syllabic)
{ta.} त +
{k} -->
 {tak} तक्
{tak} तक्
You'll notice that
{tak} has become a word with the structure CVÇ. Of course - because it can be
pronounced - is still a syllable, and V is still its Nuclear vowel
{Ñu-k~li þa.ra.}.
Contents of this page
- UKT 200814
I now have two scripts to work with: English-Latin (Eng-Lat) and
Burmese-Myanmar (Bur-Myan). They belong to two different language groups:
English to Indo-European (IE), and Burmese to Tibeto-Burman (Tib-Bur). English
is well known to the whole world, whereas Burmese is almost unknown. My task is
to bring Burmese the speech, or at least the Myanmar the script to the world's
attention, and I have to use Eng-Lat as my corresponding language whether I like
it or not. And I must know about the English alphabet - the script - as much as
possible. In another rule for Romabama, I will need to write about the Bur-Myan
Syllables in terms of Eng-Latin Letters and I will need a TOC
arranged in alphabetical order or arrangement.
English Letters belong to what I am calling a cow-shed (from Alef -
the cow, and Bet - the shed) transcribing system of recording human
speech in "scratches" - straight lines, curved lines, semi-circles,
full-circles, etc. The arrangement of Letters had developed haphazardly over
thousands of years from peoples to peoples who must have use different sets of
vocal muscles to produce human speech. It is not so with Bur-Myan, or Myanmar
Syllables which are well thought out. Now lets see what others have to say about
the English Alphabet:
From: Questions of English, compiled and edited by Jeremy
Marshall and Fred McDonald (Oxford University Press, 1996)
-
https://www.lexico.com/explore/why-is-the-alphabet-arranged-the-way-it-is
200814.
"This is an intriguing but unanswerable question. The ancestor of our
alphabet is the Phoenician alphabet of nineteen characters (representing only
consonants), dating from about the 14th century BC. Around 1000 BC this was used
as a model by the Greeks, who added characters to represent vowels. This in turn
became the model for the Etruscan alphabet, from which the ancient Roman
alphabet, and subsequently all Western alphabets, are derived. Characters have
been added over the centuries and others lost, according to the need to
represent certain sounds. But the basic order has remained the same. Indeed, it
may go back to North Semitic, the ancestor of Phoenician, which developed about
1700 BC. In other words, we do it like this because we’ve always done it like
this, but why we did it in the first place, no one knows.
"Although the order of alphabetical characters has been established for so
long, putting words into alphabetical order has been perfected relatively
recently. In medieval times this usually consisted of simply putting together
all the words beginning with a, followed by all those with b,
and so on. Strict alphabetical order did not become established until after the
advent of printing.
"Words can be alphabetized in two ways, known respectively as word-by-word
and letter-by-letter. In the former, a shorter word will precede all other words
beginning with the same sequence of letters, even if the word is followed by
another word. In letter-by-letter alphabetization, with characters are
considered as a single sequence, with any hyphens and spaces ignored."
Contents of this page
-- UKT 111231, 150407, 200811
English-Latin alphabet : The English-Latin alphabet has only 26 letters -
too limited to be transcribing Bur-Myan akshara. My first solution is to expand
the 26 letters to 52 by differentiating between
the 26 small letters and 26 capital letters.
Use of capital letters is rare in Romabama
for every day use of Burmese-to-English transcription. So it was OK for every
day use.
However,
the situation changes when Pali-Myan akshara (used for
Theravada-Buddhism), and Skt-Myan (derived from Skt-Dev for Hinduism
and Mahayana-Buddhism) are included, and I've to resort to various devices. One
of the obvious is to find single-letters for use in c2, and c4 consonants.
For c4 consonants, I simply use the capital letters: r1c4
 {Ga.}, r2c4
{Ga.}, r2c4
 {Za.}, r3c4
{Za.}, r3c4
 {Ða.}, r4c4
{Ða.}, r4c4
 {Da.}, r5c4
{Da.}, r5c4
 {Ba.}.
{Ba.}.
Then I turn to c2 consonants:
- r1c2  {hka.} --> {Ka.}/
{hka.} --> {Ka.}/
 {K}
{K}
- r2c2
 {hsa.} --> { }/
{hsa.} --> { }/
 {
}
{
}
- r3c2
 {HTa.} --> {Ha.}/
{HTa.} --> {Ha.}/
 {H} : not suitable because of absence of /tʰ/ sound
{H} : not suitable because of absence of /tʰ/ sound
- r4c2
 {hta.} --> { }/
{hta.} --> { }/
 {
}
{
}
- r5c2
 {hpa.} --> {Pa.}/
{hpa.} --> {Pa.}/
 {
} : {hpé} in my father's name U Tun Pe is the cue I'm using.
{
} : {hpé} in my father's name U Tun Pe is the cue I'm using.
To take a specific example, how are
we to represent for
 : {moaK} seems to be better than {moahk}.
The rational for this is, English
<k> is pronounced nearer to
{hka.} (IPA /k/) than
{ka.} (IPA /kʰ/). See Rule 03 for the use of capital letters
of the extended Latin alphabet. In pure Bur-Myan we do not need to kill the c2
and c4. We need to kill only the tenuis,
{ka.},
: {moaK} seems to be better than {moahk}.
The rational for this is, English
<k> is pronounced nearer to
{hka.} (IPA /k/) than
{ka.} (IPA /kʰ/). See Rule 03 for the use of capital letters
of the extended Latin alphabet. In pure Bur-Myan we do not need to kill the c2
and c4. We need to kill only the tenuis,
{ka.},
 {sa.},
{sa.},
 {Ta.},
{ta.},
{Ta.},
{ta.},
 {pa.}, and nasal
{pa.}, and nasal
 {gna.},
{gna.},
 {Ña.},
{Ña.},
 {Na.},
{Na.},
 {na.},
{na.},
 {ma.}.
{ma.}.
Finding ASCII characters for row 3 proves
to be a challenge for Romabama. Since,
I have used <t> /t/,
<d> /d/, <n> /n/ for row 4,
the only option left is to use capital
letters for row 3:
{Ta.} ,
{HTa.} ,
 {ða.}/{d³a.} ,
{ða.}/{d³a.} ,
 {Ða.}/{DD³a.} ,
{Na.}. This has proved satisfactory for Bur-Myan.
However, for Pal-Myan (Pali-Myanmar) where
row #3 is used more frequently, it is not
very convenient. Thus, how to represent
the killed-{Hta.}
{HT} (the use digraphs of in the coda position)
has become a problem.
{Ða.}/{DD³a.} ,
{Na.}. This has proved satisfactory for Bur-Myan.
However, for Pal-Myan (Pali-Myanmar) where
row #3 is used more frequently, it is not
very convenient. Thus, how to represent
the killed-{Hta.}
{HT} (the use digraphs of in the coda position)
has become a problem.
I have tried (as of 081019), using cap T underlined
{T}. e.g.
 {paaT} ,
{paaT} ,
 {þeT-nín:} (Old spelling for 'king'
- no longer listed in MLC dictionaries:
modern form is
{þeT-nín:} (Old spelling for 'king'
- no longer listed in MLC dictionaries:
modern form is
 {þa.nín:} MED2006-487c1. - personal
communication with U Tun Tint 110527. ).
However, as I delved further into Pal-Myan,
I am changing to using cap letters. Thus,
{paaHT} &
{þeHT-ning:}. As a rough rule,
cap letters are used when r3 consonants
and vowel letters are involved, e.g.
{þa.nín:} MED2006-487c1. - personal
communication with U Tun Tint 110527. ).
However, as I delved further into Pal-Myan,
I am changing to using cap letters. Thus,
{paaHT} &
{þeHT-ning:}. As a rough rule,
cap letters are used when r3 consonants
and vowel letters are involved, e.g.
 {OAk~kûT~HTa.} 'president', which on expansion becomes
{OAk~kûT~HTa.} 'president', which on expansion becomes
 . [Remember
{Ta.} and
{HTa.} are r3 consonants, and,
{U.} is the vowel-letter.]
. [Remember
{Ta.} and
{HTa.} are r3 consonants, and,
{U.} is the vowel-letter.]
Contents of this page
- UKT 200813: Pali is written in the script of the land in which it is studied.
Thus, it is written in Sinhala script in SriLanka, and in Myanmar script. The
most commonly used script all over the world is in Latin. Therefore, it is a
necessity to specify the version of Pali in which it is written as : Pali-Myan,
and Pali-Sinhala or Pali-Lanka. The International Pali is Pali-Latin.
Pali was written in Asokan-Brahmi during the time of King Asoka who flourished
some 250 years after the Buddha. King Asoka was the Emperor of almost all
ancient India, which did not include Burma. However, since Burma was part of the
area in which Magadhi culture and language had taken hold long before Buddha's
time, Buddhism must have reached Burma during Buddha's life time. I contend that
Buddha's teachings were in Myanmar script - the circularly rounded script -
which was based on a well-thought out plan. Pali was yet to be invented from
Magadha and native Lanka scripts only when Asokan missionaries arrived in the
island of Ceylon - the present Sri-Lanka.
I am studying Pali Grammar, principally by
Shin Kic'si

 {shin kic~sæÑ:} [alternate title: Kaccayana Vyakarana]
{shin kic~sæÑ:} [alternate title: Kaccayana Vyakarana]
-
PEG-indx.htm - link chk 200813
The downloaded copies that I have in TIL libraries are difficult to read in some
places and I've to rely on the version by Mazard in which the Pali is written in
Sinhala script. Unfortunately, the Sinhala script - like the Myanmar script - is
not supported by Arial Unicode font which makes my progress very slow. See what
I'm facing from the comparison of the four relevant scripts given on the right.
Contents of this page
- UKT 151220, 200811
See also Alphabetic vs. non-alphabetic writing: Linguistic fit and
natural tendencies, by Antonio Baroni, in Rivista di Linguistica 23.2
(2011), pp. 127-159, in TIL HD-PDF and SD-PDF libraries
-
ABaroni-AlphabeticNonalphabetic<Ô> /
bkp<Ô>
(link chk 200814)
It seems strange that no one seems to have recognized that since ancient times
markings or scripts have been used to record spoken language keeping
unwavering conventions. For example the sound produced in the velar region
using human sound coming through the voice-box from the lungs - which the IPA
marked as /k/ - is "recorded" with Bur-Myan glyph
{ka.} and nothing else because of which it is called "unchanging" or Akshara
{ak~hka.ra}. It further tells about the action "dance". The children are
"drilled" to articulate the sound, and write glyph at same time - impressing in
their minds the unchanging convention.
There are thousands of "recording systems" and Bur-Myan is but one. Now let's
see what the others are:
Principal sources:
- Lawrence Lo - http://www.ancientscripts.com/alphabet.html
-
Izumi Suzuka, -
http://mlcr.nagaokaut.ac.jp/main1/signs_of_syllables.htm
speaking at a student seminar in 2003 at The Laboratory of
Professor Osatospoke on Writing Systems -- Signs of Syllables had
classified writing systems into five types.
In this article, I will group the writing systems into seven groups:
1. Abjad | 2. Abugida (Akshara
{ak-hka.ra} ) |
3. Alphabet |
4. Syllabary |
5. Logogram | 6.
Proto-Writing |
7. Unknown
Each system may or may not have a clearly defined basic unit to
differentiate script (recorded on paper, etc.), and the speech-sound
(vibrational waves of air molecules) which is lost as soon it is uttered
by the speaker. Each speech-sound has two basic parts the vowel and the
consonant, and their representation the marking or glyph is also
differentiated as vowel and consonant. Our two systems of interest are
different in their basic parts. The basic part of the Abugida system [or the
Akshara-Syllable is the Syllale] and that of the Alphabet is the Letter. Thus I write:
Akshara-Syllable vs. Alphabet-Letter. The Letter, e.g. t is
mute because it lacks a vowel whereas the Akshara
{ak-hka.ra}
{ta.}
is pronounceable because of its inherent vowel.
An example of a script is Egyptian hieroglyphics which is made up of little pictures,
and we know a lot about the alphabetic system such as the Latin English script. We
know that the Chinese and their neighbours write in scripts that are
neither hieroglyphic nor alphabetic, though it was said they all had their
beginnings in little pictures. In India and Myanmarpré, we write in
characters that look alphabetic, but are not exactly so.
UKT 200814: I feel that consonants are more important than vowels in English.
Yet:
From Wikipedia:
http://en.wikipedia.org/wiki/Abjad
An abjad is a type of writing system where there is one
symbol per consonantal phoneme. Abjads differ from alphabets in that they lack
characters for vowels. Some abjads (such as the Arabic abjad) have characters
for some vowels as well, but only use them in special contexts. However, many scripts derived from abjads
have been extended with vowel symbols to become full alphabets. We cannot
definitely say that vowels are more important than consonants, since "many non-Semitic languages such as English can be written without vowels and
read with little difficulty".
"mny nn-Smtc lnggs sch `s `nglsh cn b wrttn wtht vwls `nd rd wth lttl
dffclty".
In fact, omitting vowels from
English orthography could serve to make it more phonetic without the problem of
vowel representation, as the vowels differ greatly among the different dialects of
English.
UKT 200814: Here are more examples:
wht wrds cn y rcgnz?
From: Wikipedia:
https://en.wikipedia.org/wiki/Abjad_numerals 200814
The Abjad numerals, also called Hisab al-Jummal (Arabic:
ḥisāb al-jummal), are a decimal
alphabetic numeral system/alphanumeric
code, in which the 28 letters of the Arabic alphabet are assigned numerical
values. ... ... ...
In the Abjad system, the first letter of the Arabic alphabet, ʾalif, is used
to represent 1; the second letter, bāʾ, is used to represent 2, etc. Individual
letters also represent 10s and 100s: yāʾ for 10, kāf for 20, qāf for 100, etc.
2. Abugida : Akshara-Syllable system
Alternately: Alpha-syllabary, Syllabic alphabet, or Semi-syllabary, Syllabic alphabetic.
UKT:
Abugida (or alphasyllabary) is a term coined by Peter T. Daniels
in The Worlds'
Writing Systems. The term is derived from the first four characters of an
order of the Ethiopic script. From:
http://encyclopedia.thefreedictionary.com/Abugida
An Abugida can become an Alphabet by use of a Virama
{a.þût}
'vowel-killer. Thus,
{ta.} + viram
--> თ
Note that
 'vowel-killer' is the inverse of ა 'vowel-giver'. The vowel a /a/
is the inherent vowel of the akshara.
'vowel-killer' is the inverse of ა 'vowel-giver'. The vowel a /a/
is the inherent vowel of the akshara.
South Asian scripts such as Asokan Brahmi and its descendents fit into both syllabary and alphabet. It is syllabic because the basic sign contains a
consonant and a vowel. However, every sign has the same vowel, such as /a/ in
Asokan, because of which every script of Asokan-derived languages can be
transcribed into another, such as Skt-Dev --> Pal-Myan without having to rely on
English transliterations. The basic unit is [the syllable] unchanging because of which it is
called an Akshara
{ak~hka.ra} 'unchangeable'. My system of inter-akshara change is known as
Romabama

 {ro:ma.ba.ma} "lit. the back bone of Burma".
{ro:ma.ba.ma} "lit. the back bone of Burma".
UKT: An example of an
artificial abugida in the East:
During the Chinese Yuan Dynasty (1271-1368), Kublai Khan (1215-1294) asked
Phagspa (a Tibetan Lama called Matidhvaja Sribhadra (1239-1280)) to design a
new character to be used by the whole empire. Phagspa in turn modified the
traditional Tibetian alphabet and gave birth to a new character called Phagspa
characters. These characters were not well accepted, but served only as a way
for Mongolians to learn Chinese characters and came to an end with the fall of
the Yuan Dynasty. Adapted from:
http://www.nationmaster.com/encyclopedia/Mongolian-alphabet
Pagan (the Upper Burma kingdom) was invaded by the Chinese during the Yuan
Dynasty, and my question is: Did the developers of the Myanmar script during
the Pagan period knew about the script invented by Phagspa?
UKT: One of the differences between the Roman alphabet (script for writing
English) and Myanmar akshara abugida [see below *] is the way in which the characters are arranged:
abecedary (a list of the letters in an alphabet in the some kind of order).
In English alphabet the first letter is a vowel, but the second is a consonant.
The rest of vowels are imbedded randomly among the consonants. This is not so in
an abugida where the vowels form a separate list, and the consonant letters are
in a separate list. The consonant letters are arranged in an order based on
phonetics.
* the word "abugida" is not accepted by all linguists because of which I
will be changing the name of the system to Akshara-Syllable and the
next system to Alphabet-Letter . ]
UKT: An akshara abugida like Myanmar is entirely suited to Bama (Burmese) in which the
syllables are of CV type. In cases where a consonant is included in the
coda
(end position of the syllable), the inherent vowel of that consonant has to be killed. See
Encoding Priciples. For easy reference, I have reproduced the relevant
passages below.
Internet link:
http://www.unicode.org/versions/Unicode4.0.0/ch09.pdf (page 219)
"The writing systems that employ Devanagari and other Indic scripts
constitute aksharas abugidas -- a cross between syllabic writing systems and alphabetic
writing systems. The effective unit of these writing systems is the
orthographic syllable, consisting of a consonant and vowel (CV) core and,
optionally, one or more preceding consonants, with a canonical structure of
(((C)C)C)V. The orthographic syllable need not correspond exactly with a
phonological syllable, especially when a consonant cluster is involved, but
the writing system is built on phonological principles and tends to correspond
quite closely to pronunciation."
Contents of this page
3. Alphabet : Alphabet-Letter system
C and V Alphabetic
UKT: One source of confusion in collecting materials for these articles is
because different authors use different terms for the same item. Please
remember:
The basis of an akshara is a pronounceable syllable, whereas, the basis of an
alphabet is a mute letter.
A writing system, in which consonants (C) and vowels (V) are represented
equally by separate letters. Greek and Roman alphabets,
Cyrillic alphabet, and some
artificial alphabets such as
Armenian that was invented in 405 and still in use today belong to this
category. (UKT: See an
artificial abugida.)
from:
http://mlcr.nagaokaut.ac.jp/main1/signs_of_syllables.htm
Nearly all the sounds in a language can be represented by an appropriate
consonant and vowel glyph. (UKT: Lawrence Lo had used the word "alphabet"
which I have changed to "glyph". Clicking on his link brought up a page (a
section from which is given below) in which you can see what he had meant by the
word "alphabet". It is unfortunate that he had used the word "alphabet" very
loosely.) However, just take a look at English spelling and you can almost feel
we're back to logographic systems!
UKT: The following is what Lawrence Lo had
meant by his
alphabet
"Believe it or not, the set of
characters displayed before your eyes, the
so-called Roman Alphabet, was the result of
nearly 4000 years of transformation.
"While we can claim that it was ultimately the cuneiform script which in
one way or another caused the appearance of writing systems around the
Mediterranean, in the Middle East and in India, we choose a particular script,
the Proto-Sinaitic, as the first recognizable form of the alphabet for reasons
that will become evident later on.
"Also, notice that while we are most familiar with the Roman and Greek
alphabets, there are many other alphabets and even "syllabaries" that belong
in the same family of scripts. Therefore, I'll try to incorporate as much of
these lesser known scripts as possible into this page."
You will notice that in presentation of an alphabet, we always follow a definite order. The
same is true in abugida. However one of the differences between the Roman alphabet (script for
writing English) and Myanmar abugida (akshara or
 {ak~hka.ra}) is the way in which the characters are grouped. English-script
presents all the characters in a single group, whereas Myanmar-script presents the characters in
two groups: the consonants and the vowels. The order within a group is known as abecedary
(a list of the letters in an alphabet in the some kind of order). In English-abecedary, the first
character is a vowel, but the second is a consonant. The rest of the vowels are imbedded randomly
among the consonants. This is not so in an abugida. In the consonantal-abecedary, the characters
are arranged in an order based on phonetics. The vowel-abecedary is also presented according to
phonetics, however it is not as striking as the phonetical presentation of the consonants.
{ak~hka.ra}) is the way in which the characters are grouped. English-script
presents all the characters in a single group, whereas Myanmar-script presents the characters in
two groups: the consonants and the vowels. The order within a group is known as abecedary
(a list of the letters in an alphabet in the some kind of order). In English-abecedary, the first
character is a vowel, but the second is a consonant. The rest of the vowels are imbedded randomly
among the consonants. This is not so in an abugida. In the consonantal-abecedary, the characters
are arranged in an order based on phonetics. The vowel-abecedary is also presented according to
phonetics, however it is not as striking as the phonetical presentation of the consonants.
Contents of this page
Syllabic
Writing system in which each character represents a syllable, typically consisting either CV or
V-type syllable: e.g. Japanese Katakana and Hiragana.
from:
http://mlcr.nagaokaut.ac.jp/main1/signs_of_syllables.htm
In a syllabic writing system, the overwhelming number of signs are used solely for their
phonetic values. A few non-phonetic are used for numbers, punctuation, and commonly used words.
Contents of this page
Ideogram ?
Logographic and Logophonetic
A character in writing which represents complete word is called logogram.
Examples are Chinese character, and early Egyptian hieroglyph and Sumerian
cuneiform.
from:
http://mlcr.nagaokaut.ac.jp/main1/signs_of_syllables.htm
A system of this kind uses a tremendous number of signs, each to represent a
morpheme. A morpheme is the minimal unit in a language that carries some
meaning. So, a logogram, a sign in a logographic system, may represent a word,
or part of a word (like a suffix to denote a plural noun). Because of this, the
number of signs could grow to staggering numbers like Chinese which has more
than 10,000 signs (most of them unused in everyday usage).
(UKT: It seems that in some logographic systems, there are two types of
signs, one denoting morphemes and the other denoting sound. As such, these
should be called Logophonetic.)
This is sort of like stripped down versions of
logographic systems. In essence, there are two types of signs, ones denoting
morphemes and ones denoting sound. Most of the logo-phonetic are logo-syllabic,
meaning that they denote syllables. An exception is Egyptian, whose phonetic
signs denote consonants.
Contents of this page
This is the most rudimentary type of writing system. Examples of this type
usually have small inventory of signs and large room for interpretation. They
don't denote full running texts but instead serve more like mnemonic devices for
the reader. However, they are writing systems because in some small way they do
represent the underlying language, no matter how poorly.
Contents of this page
Sometimes it is possible to infer what type a script is by counting the
number of signs it has. However, sometimes it is impossible because there aren't
enough textual evidence to establish what the type is. The most famous example
of this is the Phaistos
disc
UKT: Though we rarely pay attention to the order in which the glyphs (or
characters of a writing system), it is very important in the study of scripts.
The following passage is from
http://www.ancientscripts.com/alphabet.html
"The earliest example of an abecedary (a list of the
letters in an alphabet in the some kind of order) was found in the city of
Ugarit. This abecedary shows a total of 30 symbols used in the Ugaritic
script. However, instead of being written in some kind of linear West Semitic,
Proto-Sinaitic-derived form, the clay tablet that recorded this abecedary was
written in some kind of cuneiform. While the letters in this script were made
up of wedges and strokes, the forms of the characters were unrelated to any
other cuneiform like Sumerian or Akkadian. There is some similarity, though,
between the Ugaritic signs and linear West Semitic letters."
The word abecedary is not listed in AHTD.
Contents of this page
From Lawrence K Lo -
http://www.ancientscripts.com/ws_types.html
"You may have also encountered the term "ideographic". What it describes is
a writing system whose symbols represent ideas. So, an ideographic writing
system can be read by any person speaking any language given that they know
which symbol in the system represents which idea. However, the concept of an
"ideographic" writing system does not apply to any known writing system. Every
writing system in the world replicates a language, so it encodes sounds and
grammatical rules. Even at the most primitive level, in writing systems like Naxi or Mixtec, where extremely pictorial signs consist of the main bulk of the
system, tricks to spell names using the rebus principle can still be detected.
"Furthermore, because of the nature of language, putting words together make
more complex ideas. Since there is an infinite number of combination of words,
there clearly cannot be sufficient signs to represent each idea in a language.
So, the writing system must mimick the natural language by putting two signs
together to form a compound that represents the more complex idea. However, when
this happens, signs don't just get juxtaposed randomly, but instead in some
predescribed way that follows the grammatical rule of the language. All of a
sudden, this turns into a logographic system!
"(Lawrence Lo's) is that ideographic systems don't exist. It is a myth. Any
writing system starts off as logographic and grows from there.
"This is, of course, just my opinion, but I feel that it rests relatively
well on solid data from writing systems of the world."
Contents of this page
Footnote 01. For maps of script
and language distribution in South Asia, and further documentation, see Joseph
E. Schwartzberg (ed.), A Historical Atlas of South Asia (Chicago and
London, 1978), p. 102 et passim. For a brief account of the evolution of Indian
scripts, see Colin P. Masica, The Indo-Aryan Languages (Cambridge, 1991),
chapter 6: “Writing Systems”.
Note Internet link 1 will take you to http://www.ucl.ac.uk/~ucgadkw/members/transliteration/html/translit2.html
Footnote 02. See W. Sidney Allen,
Phonetics in Ancient India (London,
1953).
Note Internet link: 2 will take you to http://www.ucl.ac.uk/~ucgadkw/members/transliteration/html/translit3.html
Go back writing-script-note-b
Contents of this page
End of TIL file
