
Update: 2020-09-02 12:33 AM -0400
rim00.htm.htm
by U Kyaw Tun (UKT) (M.S., I.P.S.T., USA), and staff of Tun Institute of Learning (TIL).
Not for sale. No copyright. Free for everyone.
Prepared for students and staff of TIL Research Station, Yangon,
MYANMAR
-
http://www.tuninst.net ,
www.romabama.blogspot.com
index.htm |
Top
RBM-typewriter-indx.htm
General considerations:
Rime and Rhyme
Vowels ending in killed aksharas
Vowels (formed from vowel-letters) ending
in killed aksharas
Extending the vowels ending in killed
nasals
Extending the vowels ending in killed
wag-aksharas
Extending the vowels ending in killed
awag-aksharas
UKT note
Devanagari
Inherent vowel
South Asian scripts
Syllable
UKT 200827
Romabama, the almost one-to-one transcription, is essentially Burmese speech in Latin script. The effective unit of Burmese-Myanmar script - the parent of Romabama, like Sanskrit speech which writes in Devanagari script is the orthographic Syllable.
Bur-Myan, Pali-Myan, and Skt-Dev write in a speech-to-script system known as Abugida (a term which is not generally accepted). However English writes in Latin script in another speech-to-script system known as the Alphabet. The effective unit is the mute Letter. Failure to differentiate the two systems, Abugida and Alphabet, is one of the failures of the modern linguists. Since the term Abugida is not generally, I'll adopt a new terminology and different the two systems as Akshara-Syllable and Alphabet-Letter systems. The two are related as attested in the case of Bur-Myan and Georgian speech written in Mkhedruli script.
Bur-Myan uses the Akshara-Syllable and Georgian-Mkhedruli system.
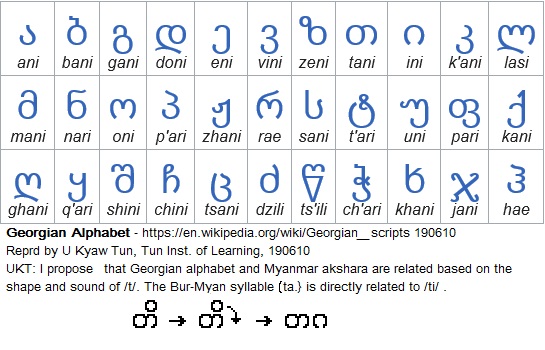

The relation between the two can be shown by comparing Burmese
consonantal-syllable
![]() {ta.}, and Georgian consonantal-letter თ «tani»
{ta.}, and Georgian consonantal-letter თ «tani»
Bur-Myan:
{ta.} + viram -->
{t}
The reverse process is
Georg-Mkhe: თ «t» + ა «a» --> თა «ta»
The canonical structure of Bur-Myan syllable is CVÇ, where is the
onset-consonant, V the nuclear-vowel
![]()
![]() {Ñu~kli þa.ra.}, and Ç the coda-consonant. A Bur-Myan word or syllable must
always have a nuclear-vowel
{Ñu~kli þa.ra.}, and Ç the coda-consonant. A Bur-Myan word or syllable must
always have a nuclear-vowel
![]()
![]() {Ñu~kli þa.ra.}, and V can never be a zero. Both C and Ç can have values 0, 1,
2, 3 depending your ability to articulate.
{Ñu~kli þa.ra.}, and V can never be a zero. Both C and Ç can have values 0, 1,
2, 3 depending your ability to articulate.
Traditionally, Bur-Myan of native origin, the coda Ç = 0 or 1 only. But in imported words in Romabama, this restriction does not hold. For words and syllables with the killed-consonant, the rime is more important than the vowel, and this chapter on the Burmese-Myanmar vowel is actually about the rhyme.
UKT 200821:
Though I'm familiar with the word "Rhyme", I wasn't sure of the word "Rime". Then I got misled by: DJPD16 p458 - Info panel 62. It states in Examples for English: "In the word <spoon> the rhyme (or rime) is /uːn/, in <tea> it is /iː/ and in <strengths> it is /eŋθs/ or /eŋkθs/."
I suspect there is some thing missing in "the rhyme (or rime)" and I must find outI always try to make sure that my English usage is correct. Is there a difference between Rime and Rhyme? Since I find that Google is good for a quick reference, I go online:
"Rimes are word parts that refer to a spelling pattern, and rimes will rhyme. Not all rimes come at the end of a word. Words with multiple syllables, have multiple rimes. ... Just as rhyme and rime sound the same, their different spelling pattern or rime, makes them two different words." - Google search 200821
In learning pronunciation of words we have to keep track of rhyme. Word-parts that refer to spelling are known as rimes, and we say that "rimes will rhyme". Rimes begin with a vowel sound and end before the next vowel sound.
UKT 200821: I still need examples from English.
From: https://sites.google.com/a/paragonscience.org/mmccluskey/rime-vs-rhyme-what-s-the-big-difference 200821
"The bold letters are the rimes: <cat>, <bat>, <mat> , or, <stale> <male> <kale> .
"Not all rimes come at the end of a word. Words with multiple syllables, have multiple rimes. For instance, the word <different> has 3 rimes: <iff>, <er>, <ent>.
"Rhyme can sound the same but be spelled differently, using different rimes: <hey> , <may> , <lei>
[UKT: Eng-Lat has only one front-mid vowel, and the example <lei> is misleading to Bur-Myan speakers.
The example should have been{lé} and not
{lè:}]
"Identifying rime is part of word study. For some students, it helps to point out the spelling patterns that sound the same, and identify which ones simply rhyme when you hear them, and which ones have matching rimes when you write them. This will be important when we talk about homophones*, as well as words with multiple meanings, and while we learn to write multi-syllable words. Think of rimes as word parts, and breaking up words into onset (beginning sound) and rime† (spelling patterns that begin with a vowel) will make more sense."
*homophones - words that sound the same but may be spelled differently.
† rime - spelling patterns that begin with a vowel.
[UKT: The author means that rime is the Nuclear vowel{Ñu-k~li þa.ra.} + coda .]
After making sure of the difference in rime and rhyme, let's continue. The nasal rimes in Bur-Myan are:
{än},
{ín},
{iñ},
{ûN},
{ûn},
{ûm},
{oän},
{OÄn}.
Note the vowel change due to the influence of coda.
Each vowel, and nasal rime can have more than
one register: differentiated by the vowel
duration in eye-blinks.
extra-short,
![]() {a:.} = 1/2 blnk
{a:.} = 1/2 blnk
creak or short
![]() {a.} = 1 blnk
{a.} = 1 blnk

modal or long
![]() {a} = 2 blnk
{a} = 2 blnk
emphatic
![]() {a:} -----
= 2 emphatic-blnk
{a:} -----
= 2 emphatic-blnk
One of difficulties in transliteration-transcription between BEPS languages is due to what I had formerly called the Two-Three tone problem. This is now resolved by taking vowel-durations in eye-blinks.
The nasal rimes becomes more complex when row #2 Palatal consonants are involved. In the following, I've given only one register, but remember there may be three: 1 blnk, 2 blnk, and 2 emphatic-blnk
{ñíñ}
{ñaañ} "bent of mind" - MLC MED2006-155c2
{Ñæñ.} "depth of night" - MLC MED2006-158c1
UKT 200808: I'm not satisfied with my above transcription, and may be changed in later editions
Formerly, I had thought that Bur-Myan,
![]() {æÑ} should be included in the nasals, but since Nya-major
{æÑ} should be included in the nasals, but since Nya-major
![]() {Ña.} has been identified as a Palatal approximant, and
{Ña.} has been identified as a Palatal approximant, and
![]() {ya.} /j/ to be the Velar approximant,
my position on killed-Nya-major
{ya.} /j/ to be the Velar approximant,
my position on killed-Nya-major
![]() {Ñ} has changed. Killed-Nya-major
{Ñ} has changed. Killed-Nya-major
![]() {Ñ}, and killed-ya'pak'lak
{Ñ}, and killed-ya'pak'lak
![]() {ý} are now treated to be similar. The syllable
{ý} are now treated to be similar. The syllable
![]() {æÑ} has the sound
{æÑ} has the sound
{ñæÑ}
{ÑæÑ:} "moan" (MLC MED2006-158)
I am now holding the view that the
British-colonialist rendering of the
name of the Myanmar-town
![]() {præÑ} as "Prome" to be an honest
attempt of following the Bur-Myan spelling
without realizing that the akshara Nya-major
{præÑ} as "Prome" to be an honest
attempt of following the Bur-Myan spelling
without realizing that the akshara Nya-major
![]() {Ña.} has a sound unique to Bur-Myan, and
that it is absent in both English and Hindi
phonologies. I am finding that IPA
transliteration-transcription for
Bur-Myan to be woefully inadequate.
{Ña.} has a sound unique to Bur-Myan, and
that it is absent in both English and Hindi
phonologies. I am finding that IPA
transliteration-transcription for
Bur-Myan to be woefully inadequate.

Leaving aside the row 3 ({Ta.} row) for the present, the c1s of r1, r2, r4, r5 would give:
. A possible Romabama transliteration is: {ak}, {is}, {ut}, {up}. You will notice the peak vowel changing from
a > i > u .
Then, for each row, we will have:
row 1
{ak} {ahk} {ag}
row 2{is} {ihs} {iz}
row 4{ut} {uht} {ud}
row 5{up} {uhp} {ub}
In the above list, row 1 {ak} is the first of the rimes:
![]() {ak}, {àk}, {aik}, {oak}, {auk} {eik}.
{ak}, {àk}, {aik}, {oak}, {auk} {eik}.
In the following formed from
![]() {ut} {àt} {ait} {oat} {ét} {aut}, {eit}, vowel-letters {I.}, {U.}, {AU.} can
also take part. My tentative rule of spelling is to
write down words formed with vowel-signs (using {a.}), and then capitalize the
letters corresponding to vowel-letters. I am finding it very unsatisfactory, and
will have to come back to it later.
{ut} {àt} {ait} {oat} {ét} {aut}, {eit}, vowel-letters {I.}, {U.}, {AU.} can
also take part. My tentative rule of spelling is to
write down words formed with vowel-signs (using {a.}), and then capitalize the
letters corresponding to vowel-letters. I am finding it very unsatisfactory, and
will have to come back to it later.
{ut~ta.}
/|a' ta.|/ - personal pronoun I. n. self. (Pali:
{ait}
/|ei'|/ - n. 1. bag; sack. -- MEDict626
{AIt~hti.ya.}/|ei' hti. ja.|/ - n. woman. (Pali: {AIt~hti.ya.})
{oat}
/|ou'|/ - n. brick (Pali:
AIT~hTa.ka.}) -- MEDict626
{OAt~ta.ra. hpa.la.gu.ni}/|ou' tara. hpala. gu. ni|/
- n. astronomy asterism of two stars in Leo resembling the rear legs of a couch. -- MEDict627
The vowels forming in killed nasals are realised in three tones as in the
case of simple vowels, e.g. {a.} {a} {a:}. In this respect they are different
form the vowels ending in killed wag-aksharas. This has led some Western
scholars to say that Burmese-Myanmar has 4 tones:
1. short, 2. medium, 3. long, and 4. checked.
row 1:
![]() {ing} {àng} {aing} {oang} {éng} {aung} {eing}
{ing} {àng} {aing} {oang} {éng} {aung} {eing}
row 2a:
![]() {iñ}
{ ìñ} {aiñ} {oañ} {éñ} {auñ} {eiñ}
{iñ}
{ ìñ} {aiñ} {oañ} {éñ} {auñ} {eiñ}
row 2b:
![]() {æÑ} {àÑ} {aiÑ} {oaÑ} {éÑ} {auÑ} {eiÑ}
{æÑ} {àÑ} {aiÑ} {oaÑ} {éÑ} {auÑ} {eiÑ}
row 3:
![]() {aN} {àN} {aiN} {oaN} {éN} {auN} {eiN}
{aN} {àN} {aiN} {oaN} {éN} {auN} {eiN}
row 4:
![]() {an} {àn} {ain} {oan} {én} {aun} {ein}
{an} {àn} {ain} {oan} {én} {aun} {ein}
row 5:
![]() {am} {àm} {aim} {oam} {ém} {aum} {eim}
{am} {àm} {aim} {oam} {ém} {aum} {eim}
There are more than one vowel-combinations for each killed consonant. Thus, for killed {ka.}, there are 6 possible combinations. The peak vowels (in Romabama syllables) are chosen to reflect the pronunciation (for which I am relying on the transliterations given in MEDict by MLC.
row 1:
![]() {ak} {àk} {aik} {oak} {ék} {auk}, {eik}
{ak} {àk} {aik} {oak} {ék} {auk}, {eik}
row 2:
![]() {is} {às} {ais} {oas} {és} {aus} {eis}
{is} {às} {ais} {oas} {és} {aus} {eis}
row 3:
![]() {uT} {àT} {aiT} {oaT} {éT} {auT}, {eiT}
{uT} {àT} {aiT} {oaT} {éT} {auT}, {eiT}
row 4:
![]() {ut} {àt} {ait} {oat} {ét} {aut}, {eit}
{ut} {àt} {ait} {oat} {ét} {aut}, {eit}
row 5:
![]() {up} {àp} {aip} {oap} {ép} {aup}, {eip}
{up} {àp} {aip} {oap} {ép} {aup}, {eip}

UKT: Please note that the Romabama peak-vowels are tentative, and I will come back to them later, after working with my peers.
The a-wag aksharas, some of them being semi-vowels themselves affect the peak vowels differently when compared to wag aksharas. At one time, almost all the a-wag aksharas in the form of killed aksharas (i.e. with {a·thut}) were used. However, at present, {ya.thut} is the only one that is commonly used. Use of {ra.thut}, {la.thut} and {wa.thut} is very rare.
The Romabama spelling for the following is still under consideration (the killed-aksharas are mute - how are they to be represented?):
{ya.thut} :
![]() {èý} {àý} {iý} {uý} {éý} {auý} {oý}
{èý} {àý} {iý} {uý} {éý} {auý} {oý}
{ra.thut} :
![]() {ar} {àr} {ir} {ur} {ér} {aur} {or}
{ar} {àr} {ir} {ur} {ér} {aur} {or}
{la.thut} :
![]() {al} {àl} {il} {ul} {él} {aul} {ol}
{al} {àl} {il} {ul} {él} {aul} {ol}
{wa.thut} :
![]() {aw} {àw} {iw} {uw} {éw} {auw} {ow}
{aw} {àw} {iw} {uw} {éw} {auw} {ow}
{tha.thut} :
![]() {ath} {àth} {ith} {uth} {éth} {auth} {oth}
{ath} {àth} {ith} {uth} {éth} {auth} {oth}
{ha.thut} :
![]() {ah} {àh} {ih} {uh} {éh} {auh} {oh}
{ah} {àh} {ih} {uh} {éh} {auh} {oh}
UKT: The characters in the above rimes are digraphs. Whether they are diphthongs or monophthongs is still up to my peers to decide. Above all, I would always emphasize that the Romabama vowels are all tentative. After all, my initial purpose is to design Romabama to write emails using only ASCII characters.
The following is a direct quotation from DJPD16 p105 - Info panel 17
coda: The end of a syllable, which is said to be made up of an ONSET, a peak and a coda. The peak and the coda constitute the RHYME (or RIME) of the syllable.
Examples for English
English allows up to four consonants to occur in the coda, so the total number of possible codas in English is very large -- several hundred in fact, e.g.:
<sick> /sɪk/
<six> /sɪks/
<sixth> /sɪksθ/
<sixths> /sɪksθs/
The central part of a syllable is almost always a vowel, and if the syllable contains nothing after the vowel it is said to have no coda ('zero coda'), e.g.
<bough> /baʊ/
<buy> /baɪ/
In other languages
Some languages (e.g. Japanese) have no codas in any syllables.
Go back coda-b
UKT 200827
The following is an edited text from Chapter 9, The Unicode Standard, version 4.0, Unicode Consortium, http://www.unicode.org/versions/Unicode4.0.0/ch09.pdf . Approx. p219
The Devanagari script is used for writing classical Sanskrit and its modern historical derivative, Hindi. Extensions to the Sanskrit repertoire are used to write other related languages of India (such as Marathi) and of Nepal (Nepali). In addition, the Devanagari script is used to write the following languages: Awadhi, Bagheli, Bhatneri, Bhili, Bihari, Braj Bhasha, Chhattisgarhi, Garhwali, Gondi (Betul, Chhindwara, and Mandla dialects), Harauti, Ho, Jaipuri, Kachchhi, Kanauji, Konkani, Kului, Kumaoni, Kurku, Kurukh, Marwari, Mundari, Newari, Palpa, and Santali.
All other Indic scripts, as well as the Sinhala script of Sri Lanka, the Tibetan script, and the Southeast Asian scripts, are historically connected with the Devanagari script as descendants of the ancient Brahmi script. The entire family of scripts shares a large number of structural features.
The principles of the Indic scripts are covered in some detail in this introduction to the Devanagari script. The remaining introductions to the Indic scripts are abbreviated but highlight any differences from Devanagari where appropriate.
Standards. The Devanagari block of the Unicode Standard is based on ISCII-1988 (Indian Script Code for Information Interchange). The ISCII standard of 1988 differs from and is an update of earlier ISCII standards issued in 1983 and 1986.
The Unicode Standard encodes Devanagari characters in the same relative positions as those coded in positions A0-F416 in the ISCII-1988 standard. The same character code layout is followed for eight other Indic scripts in the Unicode Standard: Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada, and Malayalam. This parallel code layout emphasizes the structural similarities of the Brahmi scripts and follows the stated intention of the Indian coding standards to enable one-to-one mappings between analogous coding positions in different scripts in the family. Sinhala, Tibetan, Thai, Lao, Khmer, Myanmar, and other scripts depart to a greater extent from the Devanagari structural pattern, so the Unicode Standard does not attempt to provide any direct mappings for these scripts to the Devanagari order.
In November 1991, at the time The Unicode Standard, Version 1.0, was published, the Bureau of Indian Standards published a new version of ISCII in Indian Standard (IS)13194:1991. This new version partially modified the layout and repertoire of the ISCII-1988 standard. Because of these events, the Unicode Standard does not precisely follow the layout of the current version of ISCII. Nevertheless, the Unicode Standard remains a superset of the ISCII-1991 repertoire except for a number of new Vedic extension characters defined in IS 13194:1991 Annex G-Extended Character Set for Vedic. Modern, non-Vedic texts encoded with ISCII-1991 may be automatically converted to Unicode code points and back to their original encoding without loss of information.
Encoding Principles
The writing systems that employ Devanagari and other Indic scripts constitute abugidas -- a cross between syllabic writing systems and alphabetic writing systems. The effective unit of these writing systems is the orthographic syllable, consisting of a consonant and vowel (CV) core and, optionally, one or more preceding consonants, with a canonical structure of (((C)C)C)V. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation.
The orthographic syllable is built up of alphabetic pieces, the actual letters of the Devanagari script. These pieces consist of three distinct character types: consonant letters, independent vowels [UKT: vowel letters], and dependent vowel signs [UKT: vowel signs]. In a text sequence, these characters are stored in logical (phonetic) order.
Go back Devan-note-b
by UKT
What is the inherent vowel? That has been my question ever since I came to study the akshara system of writing. To say that it is approximately the English "short-a", does not mean much for the English <a> itself has a changing nature and can mean anything to even to a "native-English" speaker. Moreover, when you say a "native-speaker", it becomes more confusing because the US-American, Australian, British, Canadian, and New Zealander speak in their own sweet ways. And unless you are familiar with the English-Latin vowels, to say that the inherent vowel is close to /a/ is meaningless.
The inherent vowel sometimes appears as a schwa in words such as {a.ni} meaning <red>. See the following on non-rhotic English dialects (spoken by South Indians, formerly dubbed "the Hindus" and Myanmars) below.
Non-rhotic dialects of English began to emerge in about the year 1600. The loss of the sound [r] is known as de-rhotacization. Evidence of the earliest date of the sound change is shown in the English word juggernaut, which is first attested in the 1630s. This represents the Hindi word jagannâth, meaning "lord of the universe"; the English spelling shows that the digraph er was chosen to represent a Hindi sound that is close to the English schwa.
A non-rhotic speaker pronounces the [r] in red, torrid, watery (in each case the [r] is followed by a vowel) but not the written [r] of hard, nor that of car or water except when the word is followed by a vowel. In most non-rhotic accents, if a word ending in written [r] is followed closely by another word beginning with a vowel the [r] is, however, sounded — as in water ice. This phenomenon is referred to as "linking [r]". Many non-rhotic speakers also insert epenthetic [r]s between vowels (droring for drawing). This so-called "intrusive [r]" is frowned upon by those who use the non-rhotic Received Pronunciation (RP) but even they frequently "intrude" an epenthetic [r] at word boundaries, pronouncing, for example, Africa and Asia as Africa-r-and Asia.
For non-rhotic speakers, what was historically a vowel plus [r] is now usually realized as a long vowel. So car, hard, fur, born are phonetically /kaː/, /haːd/, /fəː/, /bɔːn/ (see International Phonetic Alphabet for a key to phonetic symbols). This length is retained in phrases, so car owner is /kaːɹ oʊnə/. But a final schwa remains short, so water is /wɔːtə/. For some speakers some long vowels alternate with a diphthong ending in schwa, so wear is /wɛə/ but wearing is /wɛːɹiŋ/. Some pairs of words are homophonic for non-rhotic speakers but not for rhotic speakers; for example, spa and spar are pronounced identically by many non-rhotic speakers, but differently by rhotic speakers.
...
Areas with non-rhotic accents include Africa, Australia, most of the Caribbean, most of England (especially Received Pronunciation speakers), New Zealand, South Africa, the southeastern United States (although pockets of rhotic speakers do exist in the southern United States, especially in northwest Alabama, central Tennessee and peninsular Florida — in general the non-rhotic accent is more common in coastal Southern styles, while the Appalachian accent is rhotic), the northeastern United States (New England and New York State), and Wales.
Loss of the inherent vowel makes the consonant akshara loss its sound. Thus a
"killed" {ka.}
![]() is soundless.
is soundless.
Go back inhere-vow-b
Used as a title for the Hindu deity Krishna. [Hindi jagannāth title of Krishna from Sanskrit jaganāthaḥ/ lord of the world jagat moving, the world ( from jigāti he goes).; See g w ³- in Indo-European Roots. nāthaḥ/ lord Senses 1 and 2, from the fact that worshipers have thrown themselves under the wheels of a huge car or wagon on which the idol of Krishna was drawn in an annual procession at Puri in east-central India] -- AHTD
Go back Jugger-b
UKT: The following is an edited text from Chapter 9, The Unicode Standard, version 4.0, Unicode Consortium, http://www.unicode.org/versions/Unicode4.0.0/ch09.pdf . Approx. p217
The scripts of South Asia share so many common features that a side-by-side comparison of a few will often reveal structural similarities even in the modern letterforms. With minor historical exceptions, they are written from left to right. They are all abugidas (also called an alphasyllabary) in which most symbols stand for a consonant plus an inherent vowel (usually the sound /a/). Word-initial vowels in many of these scripts have distinct symbols, and word-internal vowels are usually written by juxtaposing a vowel sign in the vicinity of the affected consonant. Absence of the inherent vowel, when that occurs, is frequently marked with a special sign. In the Unicode Standard, this sign is denoted by the Sanskrit word virāma. (Burmese-Myanmar:
{a-thut} ). In some languages another designation is preferred. In Hindi, for example, the word hal refers to the character itself, and halant refers to the consonant that has its inherent vowel suppressed; in Tamil, the word puḷḷi is used. The virama sign (
{tän-hkwun} -- meaning: flag.) nominally serves to suppress the inherent vowel of the consonant to which it is applied; it is a combining character, with its shape varying from script to script.
UKT: Loss of the inherent vowel makes the consonant akshara loss its sound. Thus a "killed" {ka.}
is soundless.
Most of the scripts of South Asia, from north of the Himalayas to Sri Lanka in the south, from Pakistan in the west to the easternmost islands of Indonesia, are derived from the ancient Brahmi script. The oldest lengthy inscriptions of India, the edicts of Ashoka from the third century, were written in two scripts, Kharoshthi and Brahmi. These are both ultimately of Semitic origin, probably deriving from Aramaic, which was an important administrative language of the Middle East at that time. Kharoshthi, written from right to left, was supplanted by Brahmi and its derivatives. The descendants of Brahmi spread with myriad changes throughout the subcontinent and outlying islands. There are said to be some 200 different scripts deriving from it. By the eleventh century, the modern script known as Devanagari was in ascendancy in India proper as the major script of Sanskrit literature. This northern branch includes such modern scripts as Bengali, Gurmukhi, and Tibetan; the southern branch includes scripts such as Malayalam and Tamil.
The major official scripts of India proper, including Devanagari, are all encoded according to a common plan, so that comparable characters are in the same order and relative location. This structural arrangement, which facilitates transliteration to some degree, is based on the Indian national standard (ISCII) encoding for these scripts, and makes use of a virama. Sinhala has a virama-based model, but is not structurally mapped to ISCII. Tibetan stands apart, using a subjoined consonant model for conjoined consonants, reflecting its somewhat different structure and usage. The Limbu script makes use of an explicit encoding of syllable-final consonants.
Many of the character names in this group of scripts represent the same sounds, and naming conventions are similar across the range.
UKT: The following is a direct quotation from DJPD16 p522 - Info panel 72
p522. A fundamentally important unit -- the most basic unit in speech. Here we are concerned with the phonological notion of the syllable.
Examples for English
Phonologists are interested in the structure of the syllable, since there appear to be interesting observations to be made about which phonemes may occur at the beginning, in the middle and at the end of syllables. In English, it is possible to have from zero to up to three consonants in the ONSET of a syllable, and from zero to up to four in the CODA.
The study of sequences of phonemes is called 'phonotactics', and it seems that the phonotactic possibilities of a language are determined by syllabic structure. This means that any sequence of sounds that a native speaker produces can be broken down into syllables without any segments being left over. For example, in <Their strengths triumphed frequently>, we find the rather daunting sequences of consonant phonemes /ŋθstr/ and /mftfr/ , but using what we know of English phonotactics we can split these clusters into one part that belongs to the end of one syllable and another part that belongs to the beginning of another. Thus the first one can only be divided /ŋθ | str/ or /ŋθs | tr/ and the second can only be /mft | fr/ .
Phonological treatments of syllable structure usually call the first part of a syllable the ONSET, the middle part the 'peak' and the end part the CODA. The combination of peak and coda is called the RHYME. Syllable breaks, however, may be problematic, when approximants occur at syllable boundaries.
End of TIL file