a1Sa1-023top-7.htm
from: Online Sanskrit Dictionary, February 12, 2003 . http://sanskritdocuments.org/dict/dictall.pdf 090907
Downloaded, set in HTML, and edited by U Kyaw Tun, M.S. (I.P.S.T., U.S.A.), and staff of TIL Computing and Language Centre, Yangon, Myanmar. Not for sale. No copyright. Free for everyone.
indx-E4MS | |Top
SED-vow-a1-indx.htm
UKT notes
• Ashtavakra
• Austro-Asiatic languages
• bandha
• centum-satem languages
(चेन्तुम् centum :
need to check Hindi-transcription - 100228 - शतम्
śatam)
• shibboleth
UKT: How come we ended up assigning the grapheme
{sa.} to two different sounds: the palatal-stop /c/ and fricative-alveolar /s/ ? . As a stop-gap measure, I have to use a property of the Burmese-Myanmar where the coda and the onset of disyllabic words like
{thic~sa} have the /c/ and /s/ sounds for the same grapheme
{c} (without the inherent vowel), leaving the onset as
We find a similar situation in English-Latin <success> /sək'ses/ for the grapheme <c>. The English grammarians solve this problem by stating that there is no palatal /c/ in English, and assign the coda <c> to /k/.
The Sanskrit grammarians solve a similar situation by assigning r2c1 च to /ʧ/. This sound is the Burmese-Myanmar medial{kya.} and is not exactly like
{hkya.}, where the
For the fricative the Sanskritists chose the grapheme ष . We note that this grapheme is an adaptation from प. The problem I am finding with this pair is non-similarity of the phonemes: ष /s/ and प /p/.
The Myanmar grammarians (I don't known when and who - obviously of bygone days, to whom I pay respect on my bended knees and cupped palms, even though I object to their choice) dutifully follow the Sanskritists and chose a similar pair
{Sa.} [Unicode 1051] -
{pa.} [Unicode 1015] . But, I am still curious about the similarities in shapes of graphemes: प /p/ and ष /s/ in Devanagari, and
{a.pa.} - a1pa1-013top-3.htm
UKT: The Myanmar grammarians - undoubtedly the Bur-Myan monks who had become highly influenced by the Pali of the Sri Lanka
{þi-hoL} - had followed the Sanskritized Pali. I conjecture that the ancient scholar-monks from the country of Myanmar (some undoubtedly of non-Burmese ethnicity), like their brethrens from other lands such as those from China and India must have been travelling, visiting the sacred Buddhist sites in India and Sri Lanka. Their lingua franca must have been Sanskritized Pali. -- UKT110518
Some of the more famous Chinese pilgrims were Fa-hsien (399 to 414), Xuan-zang (629-645), and I-tsing (671-695). -- http://www.silk-road.com/artl/buddhism.shtml 110518
See The Unicode Standard, Version 4.0 , Codes Charts: South-East Asian scripts (from PDF Version), Unicode Consortium, Copyright 1991-2003 Unicode, Inc. http://www.unicode.org/charts/ and The Unicode Standard, Version 5.2 http://www.unicode.org/charts/PDF/U1000.pdf accessed: 100308.
I propose that we do not introduce a new grapheme for the fricative and be content to differentiate only in Romabama as
{S} for the coda.
UKT: Now let us pick a subject which might throw some light on the impact between Indo-European (represented by English) and Tibeto-Burman (represented by Burmese) groups in areas south of the Himalayas (the present-day Bangladesh, India, Myanmar, Pakistan and Sri Lanka). We will have to take into consideration the Austro-Asiatic (represented by Mon) and the Dravidian groups later.
Concentrating on Indo-European (IE) languages, we find that there are two main groups of languages under the names Centum and Satem languages: my Burmanization - Centum{ké:n-tûm}, and Satem
{sa.tûm}.
We shall concentrate on two languages that we know relatively well: English (representing Centum) and Sanskrit (representing Satem).
I am wondering if this /c/-/s/ problem is the basis of the Biblical story of Shibboleth. Even if it is not, it is interesting to note that fricatives and sounds near the fricatives are always a problem for various linguistic groups.
A similar case is met in Myanmar-country in most Karens who cannot differentiate the sounds of{sa:} 'to eat' and
{hsa:} 'salt'. Also it is quite frequent that non-Karen children educated by Karen teachers such as my own wife Daw Than Than had failed to differentiate these two sounds. After years of self-correction, she finally resolved the problem herself. It is my opinion that this particular problem is the failure to make effective use of the 'glottal' {ha.hto:} sounds.
See my collections on Centum-Satem languages. - UKT note 100228 rewritten on 110520
•
अष्ट aṣṭa
(ashhTa)
Skt:
अष्ट aṣṭa
(ashhTa) - eight - OnlineSktDict
Pal: अट्ठ aṭṭha
- num. eight: °aka, n. an octad, set of
eight - UPMT-PED008
Pal: {ûT~Hta.}
![]() - UHS-PMD0024
- UHS-PMD0024
•
अष्टदलकमलबन्ध
(ashhTadalakamalabandha)
Skt:
अष्टदलकमलबन्ध
(ashhTadalakamalabandha) - eight-petalled lotus pattern, a form of bandha poetry
- OnlineSktDict
I cannot find anything on bandha poetry on the Internet - UKT 100415.
See my note on Bandha .
¤ Skt: अष्ट
aṣṭa eight = अ ष ् ट -
SpkSkt
¤ Skt: अष्टमः, -मी,
-मम् aṣṭamaḥ,
-mī, -mam adj. eighth - SpkSkt
¤ Skt: अष्टमी
aṣṭamī f. eighth - SpkSkt
¤ Skt: अष्टमः
aṣṭamaḥ m. eighth -
SpkSkt
¤ Skt: अष्टमम्
aṣṭamam n. eighth - SpkSkt
¤ Skt: अशीति aśīti m. eighty - SpkSkt
¤ अष्टादश
aṣṭādaśa adj.
eighteenth - SpkSkt
¤ अष्टात्रिंशत्
aṣṭātriṃśat num.
thirty-eight - SpkSkt
¤ अष्टाविंशति
aṣṭāviṃśati num.
twenty-eight - SpkSkt
¤ अष्टम
aṣṭama m.
eighth part - SpkSkt
¤ अष्टवादने
aṣṭavādane
at eight o'clock - SpkSkt
¤ अष्ट वादन पर्यन्तम्
aṣṭa vādana
paryantam indecl. until eight o'clock -
SpkSkt
¤ अष्ट पर्णानि सन्ति
aṣṭa parṇāni santi
There are eight leaves - SpkSkt
•
अष्टधा
(ashhTadhaa)
Skt:
अष्टधा
(ashhTadhaa) - eightfold - OnlineSktDict
•
अष्टदश aṣṭadaśa
Skt:
अष्टदश aṣṭadaśa
(ashhTaadasha) - eighteen - OnlineSktDict
¤ अष्टदश
aṣṭadaśa m.
eighteen - SpkSkt
•
अष्टावक्र
(ashhTaavakra) .
Skt:
अष्टावक्र
(ashhTaavakra) - name of a deformed (at eight places) sage - OnlineSktDict
See my notes on Ashtavakra .
•
अष्टोत्तरीदशा
(ashhTottariidashaa)
Skt:
अष्टोत्तरीदशा
(ashhTottariidashaa) - A lunar based Dasha system uses 108 yr cycle and one
chooses it according to certain criteria - OnlineSktDict
•
अष्टौ
(ashhTau)
Skt:
अष्टौ
(ashhTau) - eight - OnlineSktDict
•
अष्तकवर्ग
(ashhtakavarga)
Skt:
अष्तकवर्ग
(ashhtakavarga) - A predictive method of Astrology that uses a system of points
based upon planetary positions - OnlineSktDict
From Wikipedia: http://en.wikipedia.org/wiki/Ashtavakra 100228
Ashtavakra was a sage in ancient India. Ashtavakra, also spelt as Ashtaavakra in Skt: अष्टवक्र means "eight bends". Ashta means eight. Vakra means bend or deformity.
In ancient India, the sage Ashtavakra was known to be a very intelligent and spiritually well advanced rishi who realized self or Atman. More information about his birth and life comes from the Indian epic Ramayana. Sage Uddalaka ran a school (Ashram) teaching Vedic knowledge. Kahoda was one of his best disciples. Uddalaka was so pleased with him that he had his daughter Sujata married to him. Sujata, eventually got pregnant and in the natural desire of wanting her child to imbibe spirituality and intelligence, began to sit in the classes taught by Uddalaka and Kahoda, listening to their chanting of mantras.
In India, there is a belief that when expectant mothers expose themselves to spiritual teachings, the child in the womb hears it and gathers that knowledge and become a genius in that spiritual area after its birth. It was one day, as Kahoda recited the Vedas, and within hearing distance of the child growing in the womb, that it heard the recitation but, since it was already aware of the correct pronunciation of every syllable since its mother used to attend classes with rapt attention, whenever Kahoda pronounced a syllable wrong, the child in the womb squirmed in distress. Sujata informed Kahoda that he had pronounced the syllable wrongly as indicated by the child in the womb. This happened on eight occasions. Kahoda perceived this as arrogance on the part of something, yet to manifest itself in the world, and he cursed the foetus with eight deformities. So, when the baby was born, it had eight bends, was crooked in eight places. Naturally, he was named Ashtavakra (Eight Bends).
Around the time Ashtavakra was born, his father was invited to argue with the great philosopher, Bandi. In those days, philosophical arguments were commonplace and the best were invited to argue in the presence of the monarch Janaka. Bandi was supposedly the son of Varuna - the Lord of all water bodies - and was sent incognito to land to get rishes, or sages, to conduct a ritual that his father wanted to perform. Bandi was well known as a philosopher and easily defeated Kahoda. As per the rules of the contest, Bandi's victims had to 'drown' themselves in the river nearby (Ganges?). Nobody knew of Bandi's real identity or his intention in demanding that his victims should submerge in the river. Kahoda, too, lost the argument and had to submerge himself in the river. Ashtavakra was therefore raised by Uddalaka and his disciples and within a short time mastered everything that was expected of a 'Brahmin'. Uddalaka and his disciples took pains to see that Ashtavakra was always kept in the dark about the fate of his father. However, Ashtavakra came to know the truth when his young uncle, Shwetaketu advertently, blurted out that the person who Ashtavakra thought was his father, was, in fact, not his father. Ashtavakra then demanded the truth from his mother and decided to confront Bandi and defeat him in an argument.
Ashtavakra then made his way to the King's palace and presented himself as a challenger. The kind-hearted King could not bear the thought of someone so young losing to Bandi and meeting the same fate as countless other Brahmins and tried to dissuade the young boy. Ashtavakra, was, however adamant, and after an initial test, Janaka decided to let him face Bandi. Ashtavakra won the argument and demanded that Bandi restore to life all the sages and Brahmins he had forced to be drowned. One of the conditions of the contest was that if Bandi loses he would grant any wish of his vanquisher. By this time, Varuna's ritual was also complete and he had rewarded all the sages and Brahmins and so when Bandi was defeated, he revealed his true identity and the reason behind the 'drowning' of his victims. At Bandi's request, Varuna bade the sages and Brahmins farewell and brought them to surface. Kahoda was extremely pleased with his son's intelligence and knowledge.
Later Ashtavakra grew into a spiritually advanced rishi and realised Atman. He went to Mithila and instructed King Janaka about the concept of Atman. These teachings form the content of the Ashtavakra Gita or Ashtavakra Samhita as it is sometimes called.
UKT: End of Wikipedia article.
Go back Ashtavakra-note-b
From Wikipedia : http://en.wikipedia.org/wiki/Austro-Asiatic_languages 100308

The Austro-Asiatic languages are a large language family of Southeast Asia, and also scattered throughout India and Bangladesh. The name comes from the Latin word for "south" and the Greek name of Asia, hence "South Asia." Among these languages, only Khmer, Vietnamese, and Mon have a long established recorded history, and only Vietnamese and Khmer have official status (in Vietnam and Cambodia, respectively). The rest of the languages are spoken by minority groups. Ethnologue identifies 168 Austro-Asiatic languages. These are traditionally divided into two families, Mon-Khmer and Munda, but two recent classifications have abandoned Mon-Khmer as a valid node, although this is tentative and not generally accepted.
Austro-Asiatic languages have a disjunct distribution across India, Bangladesh and Southeast Asia, separated by regions where other languages are spoken. It is widely believed that the Austro-Asiatic languages are the autochthonous languages [or indigenous languages - http://en.wikipedia.org/wiki/Autochthonous_language 100308] of Southeast Asia and the eastern Indian subcontinent, and that the other languages of the region, including the Indo-European, Kradai, Dravidian and Sino-Tibetan languages, are the result of later migrations of people.
The Austro-Asiatic languages are well known for having a "sesqui-syllabic" pattern, with basic nouns and verbs consisting of a reduced minor syllable plus a full syllable. Many of them also have infixes.
UKT: More in the Wikipedia article.
Go back austro-asiatic-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Bandha 100415
Bandha (Sk: बन्ध -binding, bond, arrest, capturing, putting together etc.[1]) is a term often employed in relation to yogic discourse and instruction. [UKT ¶]
The term denotes a binding, lock or bondage that may be either internal or external to the body. Bandha may be defined as a particular focused and intentional action involving pressure, contraction or force on the muscles or some other bodily or sensate phenomena. In yogic traditions, bandha are to be studied, maintained and held principally whilst engaged in pranayama. [UKT ¶]
In Jainism, bandha, refers to the karmic process of binding of material karmic particles to the soul consciousness. This bondage is on account of kasaya or passions of the soul. As per ancient Jain text of Tattvarthasutra, bandha is one of the tattva or fundamental truth of this world. As such the samsaric soul is always found in bondage with the karma since time immemorial.
UKT: Do not forget that Jainism, like Buddhism rejects the 'indestructible soul', so the above paragraph must be read with caution. Jain texts like those in Theravada Buddhist texts were written in Pali.
¤ Pal: bandha - m. binding, bond, union, bondage - UPMT-PED156
¤ Pal:{bûn~Da.} - - UHS-PMD0699
Various bandhas are described and elucidated in Yogic texts and discourse. However, rarely is an exegesis of Bandha provided. Bandhas have been described in Hatha Yoga Pradipika in the chapter relating to Mudras. Ten mudra are codified in this treatise. Of marked importance, the chapter describes all bandha as mudra.[2]
Bandha are employed in Hatha Yoga. Hatha Yoga holds that there are four types of bandhas, Jalandhara Bandha, Uddiyana Bandha, Mula Bandha and Maha Bandha which have been codified in many ancient texts.[3]
• ("bond/bondage"): the fact that human beings are typically bound by ignorance (avidya), which causes them to lead a life governed by karmic habit rather than inner freedom generated through wisdom (vidya, jnana) [4]
• (lit. stop, block or lock). It means stopping or blocking the flow of spiritual energy in a specific channel (nadi) of the body by a particular yogic posture. It also means getting rid of the cycles of birth and death.[5]
UKT: End of Wikipedia article.
Go back bandha-note-b
UKT:
How come we ended up assigning
![]() {sa.}
to two different sounds: the palatal-stop /c/ and fricative-alveolar /s/ ? .
As a stop-gap measure, I have to use a property of the Bur-Myan (Burmese-Myanmar) where
the coda and the onset of disyllabic words like
{sa.}
to two different sounds: the palatal-stop /c/ and fricative-alveolar /s/ ? .
As a stop-gap measure, I have to use a property of the Bur-Myan (Burmese-Myanmar) where
the coda and the onset of disyllabic words like
![]() {thic~sa} have the /c/ and /s/ sounds for the same grapheme
{thic~sa} have the /c/ and /s/ sounds for the same grapheme
![]() {sa}.
Since the coda is a killed consonant, I can legitimately write
{sa}.
Since the coda is a killed consonant, I can legitimately write
![]() {c} (without the inherent vowel), leaving the onset as
{c} (without the inherent vowel), leaving the onset as
![]() {sa.}.
The result is
{sa.}.
The result is
![]() {thic~sa}.
{thic~sa}.
We find a similar situation in English-Latin <success> /sək'ses/
for the grapheme <c>. The English grammarians solve this problem by stating
that there is no palatal /c/ in English, and assign the coda <c> to /k/. The
Sanskrit grammarians solve a similar situation by assigning r2c1 च to /ʧ/.
This sound is the Bur-Myan medial
![]() {kya.}
and is not exactly like
{kya.}
and is not exactly like
![]() {hkya.}.
{hkya.}.
![]() {hkya.}
is the familiar /ʧ/ sound of the English-Latin <church> /ʧɜːʧ (US) ʧɝːʧ/.
{hkya.}
is the familiar /ʧ/ sound of the English-Latin <church> /ʧɜːʧ (US) ʧɝːʧ/.
Leaving aside the Bur-Myan language - the typical Tibeto-Burman (Tib-Bur) language, and Pal-Myan - presumably a Tib-Bur language, for a while, we will concentrate on Indo-European (IE) languages. In IE, we find two main groups under the names Centum and Satem.
To keep my thinking straight, I will pronounce the <c> in 'Centum' as /k/ in <cat> /kæt/, and Burmanize 'Centum' to
We will keep in mind that English is a Centum
The following are my collections on Centum-Satem. - UKT note 091215
In a lecture given in 1786, Sir William Jones, Chief Justice of India and founder of the Royal Asiatic Society, noted the strong relationship in verbal roots and the grammatical forms of Sanskrit, Greek, and Latin. This similarity, he remarked, could not have been produced by accident; these languages must have originated from a common source. He added that Gothic, Celtic, and Old Persian may have come from the same origin. Others had also noted the similarity between Sanskrit and other languages by comparing words from different languages. Though he was not the first, Jones is often credited with the birth of Indo-European linguistics by eloquently stating that a common source, later to be identified as Proto-Indo-European [PIE], was the ancestor of these related languages.by Deborah Anderson, Dept. of Linguistics, Univ. of California, Berkeley, http://popgen.well.ox.ac.uk/eurasia/htdocs/anderson.html 091215
The discovery of sound laws in the 1860's helped to establish the foundation of comparative Indo-European [IE] linguistics. It is upon such regularly occurring sound laws that allowed comparisons to be made; exceptions to the laws needed to be explained. Today the study of IE linguistics draws on work done in phonetics, dialectology, typology, and other fields but the basis of comparison still rests on the set of correspondences between the languages.

In Sanskrit, Avestan, Lithuanian, and Old Church Slavic the initial consonant appears as an s- (or sh-) sound (a sibilant), whereas Greek, Latin, Old Irish, Welsh, English, and Tocharian have a k- sound (a velar or a palato-velar). This correspondence, mirrored in many other word sets, was identified as an important Indo-European isogloss (a boundary line that can be drawn based upon a particular linguistic feature): Indo-Iranian, Baltic, Slavic, Albanian, and Armenian have a sibilant for PIE *k' whereas Greek, Latin, Celtic, Germanic and Tocharian maintain the k- sound. Those languages with the s- (sh-) sound are classified satem (after the 'hundred' word in Avestan), those which have a k- sound are the centum languages (after the Latin word).UKT: The <s> in IAST (International Alphabet for Sanskrit Transcription) of "satam" can be one of the three: श ś , ष ṣ , स s . Whatever the IPA narrow transcription may be, to a Bur-Myan ear (particularly myself) they sound like /ʃ/, /s/, /θ/, and I have identified them to be Bur-Myan
{þhya.},
{þa.} (spelling according to MLC). [ Note: MLC MED2010-610 is still using
Because of the need to incorporate sibilant sounds, Romabama has to adopt two sets of graphemes for
¤ for alveolar-fricative,
¤ for palatal-stop,
SpokenSkt: www.spokensanskrit.de gives (100227) the following:
¤ शतम् śatam ... hundred - /{þhya.tûm}/
¤ द्विशत dviśata adj. two hundred
¤ शततम śatatama adj. one hundredth
¤ सुवर्णशत suvarṇaśata n. hundred golden coins
The initial consonant in "satam" in this article is clearly श ś {sha.} (sibilant), and NOT स s {þa.} (thibilant).
Note that Tocharian, found in far western China, is a centum language as is Hittite (found in Anatolia) so that a strict satem = east, centum = west rule-of-thumb doesn't work.
The original form of the word for 'hundred' in Proto-Indo-European was *(d)kmtom [k with an acute above it or k' can be used; dot under m; acute on o], which shows that the centum group has actually retained the original sound of the velar but the satem group has changed the sound; it moved the articulation forward in the mouth.
The satem/centum grouping holds fairly well for the outcomes of other dorsals (that is, all kinds of k-sounds) in Indo-European. The example above demonstrates the outcome for PIE *k' [k with an acute above it or k' can be used]. By looking at various correspondences, a table can be created showing the various outcomes in the different languages (adapted from Beekes 1995: 110). The reconstructed Proto-Indo-European form is on the left, the outcomes which appear in cognate words to the right. (The variant outcomes listed below depend largely upon preceding or following sounds or position in a word, particularly initial position. For details on the particular environments, compare Beekes).
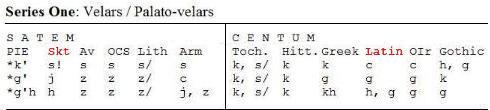
A second series has been postulated, the plain velars. However, no IE language clearly retains all three series. (There is some debate about whether Albanian retains all three.) As reflected in the chart below, satem has either a velar or sibilant, centum has either a velar (or palato-velar) or labiovelar. The plain velars occur only in certain environments, i.e., only after *u and *s and before *r and *a, so they appear to be conditioned variants of the other series.

A third series is well attested, the labiovelars, which combine the velar with a labial element (represented by the superscripted w). Note that in the satem languages, the labial element is lost. Once again, the satem languages differ from the reconstructed Proto-Indo-European forms in having lost the labializing element..
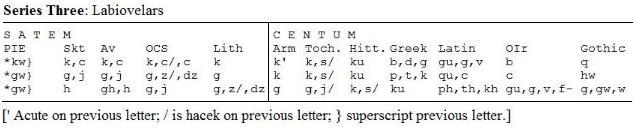
The satem/centum distinction is evident in the outcomes listed above and is an important isogloss. What does it indicate in terms of IE origins and IE distribution? As observed above, the centum languages retain the PIE articulation better than the satem group: the velars (/palato-velars) in the centum group did not become sibilants and the labial element was retained. In dialect geography, the more conservative elements are retained in the geographic periphery, away from the central area where innovation is taking place (in this case, where the satem languages are). Using the satem/centum isogloss as a guide, Indo-Iranian, Baltic, Slavic, Armenian, and Albanian serve as one central area. However, it is important to also take into consideration other isoglosses in arriving at an adequate model for the PIE situation.
Beekes, Robert S.P. Comparative Indo-European Linguistics: an introduction. Amsterdam/Philadelphia: John Benjamins, 1995. [A useful handbook now out in paperback. Centum / satem discussion is found on pages 109-113 and 129.]
Sihler, Andrew L. New Comparative Grammar of Greek and Latin. New York and Oxford: Oxford University Press, 1995. [This topic is discussed on pages 7, 151-154.]
UKT: End of article © 1998 by Deborah Anderson
From Wikipedia: http://en.wikipedia.org/wiki/Centum-Satem_isogloss 091215

The Centum-Satem division is an isogloss of the IE language family, related to the different evolution of the three dorsal consonant rows of the mainstream reconstruction of PIE :
*kʷ, *kʷʰ, *gʷ,
*gʷʰ (labiovelars)
*k, *kʰ,
*g, *gʰ
(velars)
*ḱ, *ḱʰ,
*ǵ, *ǵʰ
(palatovelars)
Nineteenth-century Indo-European linguists, such as Karl Brugmann, tended to reconstruct four articulation series as shown above. After the 1891 discovery by Ferdinand de Saussure that tʰ came from t followed by a laryngeal, all the unvoiced aspirates were removed from the reconstruction on the assumption that they all came from unaspirated dorsals followed by laryngeals, a too hasty assumption, as it turns out.[1] The three-series view persisted until the late 20th century.[2] More recently Szemerényi reports: "... it seems to be empirically established that voiced aspirates exist only in languages which also have unvoiced aspirates ...."; that is, the three-series view is impossible. This discovery lends support to the restoration of the unvoiced aspirates to the model. The question, however, has no bearing on existence of the isogloss, which was established from comparative lexical data.
The terms Centum Group and Satem Group come from the words for the number "one hundred" in a traditional representative language of each group: Latin centum and Avestan satəm. The initial consonant in these two examples comes from the Indo-European palatal consonant, *ḱ, which became in the first case a simple velar, and in the second a sibilant.
The Satem languages (which have the sibilant where the centum equivalents have the velar) include Indo-Iranian, Armenian, Balto-Slavic, Albanian, and perhaps also a number of barely documented extinct languages, such as Thracian-Dacian.[3] This group changed PIE-palatovelars into sibilants, retaining PIE-velars and merging PIE-labiovelars into them to form an expanded velar group. The plain velars and the labiovelars were not merged in Proto-Albanian.[4] Balto-Slavic evidences Centum development in some words and Satem in others, from which it may be concluded:[5] "It is therefore much more likely that each branch became centum or satem independently."

The Centum group, often incorrectly presented as being identical to "non-Satem", i.e. as including all remaining dialects,[6] was in fact created by its own sound change independent from and predating the Satem sound change. PIE-palatovelars were merged into PIE-velars to create an expanded velar inventory overlapping on but different from the satem inventory. The Centum group includes Italic, Celtic, Germanic, Hellenic and possibly a number of lesser-known extinct groups (such as Ancient Macedonian and Venetic). Tocharian combined all rows into a single velar row by merging the palatovelars into the velars as in Centum and the labiovelars into the velars as in Satem, allowing two points of view: either Tocharian does not fit the model[7] or it is a Centum language.[8] The Proto-Anatolian language apparently did not undergo either the Satem or the Centum sound change, as the velar rows remain separate in Luwian.[9] The closely related Hittite is a Centum language, which it may have become secondarily, but the exact sequence is unclear.[10]
The isogloss only applies to the parent language with the full inventory of dorsals. Later sound changes within a specific branch of Indo-European that are analogous to one of the Centum or Satem changes, such as the palatalization of Latin k to s in some Romance languages or the merger of *kʷ with *k in the Goidelic languages, are excluded.
August Schleicher, an early Indo-Europeanist, in Part I, "Phonology", of his major work, the 1871 "Compendium of Comparative Grammar of the Indogermanic Language", published a table of original momentane laute, or "stops", that has only a single velar row, *k, *g, *gʰ, under the name of gutteralen.[11][12] He does identify four palatals (*ḱ, *ǵ, *ḱʰ, *ǵʰ) but hypothesizes that they came from the gutterals along with the nasal ń and the spirant ç.[13]
Karl Brugmann in his 1886 equivalent work, "Outline of Comparative Grammar of the Indogermanic Language," promotes the palatals to the original language, recognizing two rows of Explosivae, or "stops", the palatal (*ḱ, *ǵ, *ḱʰ, *ǵʰ) and the velar (*k, *g, *kʰ, *gʰ),[14] each of which was simplified to three articulations even in the same work.[15] In that same work Brugmann notices among die velaren Verschlusslaute, "the velar stops", a major contrast between reflexes of the same words in different daughter languages: in some the velar is marked with a u-Sprache, "u-articulation," which he terms a Labialisierung, "labialization," in accordance with the prevailing theory that the labiovelars were velars labialized by combination with a u at some later time and not among the original consonants. He divides languages therefore into die Sprachgruppe mit Labialisierung[16] and die Sprachgruppe ohne Labialisierung, "the language group with (or without) labialization," which are perforce identical to the Centum and Satem groups. He opines that[17]
The doubt introduced in this passage suggests he already suspected the "afterclap" u was not that but was part of an original sound.
In 1890 Peter von Bradke published "Concerning Method and Conclusions of Aryan (Indogermanic) Studies" in which he saw the same division (Trennung) as did Brugmann but he defined it in a different way. He said that the original Aryans knew two kinds of gutteraler Laute, or "gutteral sounds," the gutterale oder velare, und die palatale Reihe, "gutteral or velar and palatal rows," each of which were aspirated and unaspirated. The velars were to be viewed as gutterals in an engerer Sinn, "narrow sense." They were a reiner K-Laut, "pure K-sound." Palatals were häusig mit nachfolgender Labialisierung, "frequently with subsequent Labialization." This latter distinction led him to divide the palatale Reihe into a Gruppe als Spirant and a reiner K-Laut, typified by the words satem and centum respectively.[18] Later in the book[19] he speaks of an original centum-Gruppe from which on the north of the Black and Caspian Seas the satem-Stämmen dissimilated among the Nomadenvölker, or Steppenvölker, located there by further palatalization of the palatal gutterals.
By the 1897 edition of Grundriss, Brugmann (and Delbrück) had adopted Von Bradke's view. He says[20]
Concerning the labialized velars Brugmann had changed his mind, and there was no more mention of labialized and non-labialized language groups. The labio-velars now appeared under that name as one row of the 5-row Verschusslaute (Explosivae) containing die labialen V., die dentalen V., die palatalen V., die reinvelaren V. and die labiovelaren V. It was Brugmann who pointed out that labiovelars had merged into the velars in the Satem Group,[21] accounting for the coincidence of the discarded non-labialized group with the Satem Group.
The presence of three dorsal rows in the proto-language is one hypothesis of many.[2] In another hypothesis by Antoine Meillet the original rows were the labiovelars and palatovelars, with the pure velars being allophones of the palatovelars in some cases, such as depalatalization before a resonant.[22] Other possibilities are borrowing between early daughter languages during the process of Satemization, or perhaps the concept of original velars is an artifact based on just plain false etymologies in modern times. Oswald Szemerényi proposed that the "preconsonantal palatals probably owe their origin, at least in part, to a lost palatal vowel;" that is, a velar was palatalized by a following vowel subsequently lost.[23] The palatal row therefore post-dated the original velar and labiovelar but Szemerényi does not give times. He includes the palatals in a table of five rows stops "shortly before the break-up" with a question mark after them. Other scholars who assume two dorsal rows in PIE include Kuryłowicz (1935), Meillet (1937), Lehmann (1952), and Woodhouse (1998).
The Satem languages show characteristic affricate and fricative consonants articulated in the front of the mouth in inherited Indo-European lexical items in which in other languages termed the Centum Languages pure velars and labiovelars, sounds articulated at the back of the mouth, are found. The Satem shift is conveniently illustrated with the word for '100', Proto-Indo-European *(d)ḱm̥tóm, which became Avestan satəm (hence the name of the group), Persian sad, Sanskrit śatam, Latvian simts, Lithuanian šimtas, Old Church Slavonic sъto. Another example is the Slavic prefix sъ(n)- ("with"), which appears in Latin, a centum language, as co(n)-; conjoin is cognate with Russian soyuz("union").
The sources of the satem sounds and the methods by which they became what they are have been debated heavily by Indo-European linguists for many decades. The originator of the concept, Peter von Bradke, believed in a Proto-Indo-European two-row system of four gutterals each row, the pure velar row: *k, *kʰ, *g, *gʰ, and the palatovelar row: *ḱ, *ḱʰ, *ǵ, *ǵʰ. For example, *ḱ became Sanskrit ś [ɕ], Latvian, Avestan, Russian and Armenian s, Lithuanian š [ʃ], and Albanian th [θ] (but k before a resonant). Karl Brugmann added the labio-velar row: *kʷ, *kʷʰ, *gʷ, *gʷʰ, with the proviso that in the Satem languages it merged into the velar row, losing their accompanying lip-rounding. This merger left the Satem group without labio-velars. Regardless of whether satem words were created from those rows with those articulations in that way, they are definable as satem words.
Satem-like features have arisen multiple times during history (e.g. French cent pron. [sã]). As a result, it is sometimes difficult to firmly establish which languages were part of the original Satem diffusion and which were affected by secondary assibilation in a later time period. For instance, it is known that the assibilation found in French and Luwian were later developments as linguists have extensive documentation of Latin and Hittite. However, in the case of Dacian and Thracian, there is not enough information on the history of these languages to conclusively settle the issue of when their Satem-like features originated. Extensive lexical borrowing, such as Armenian from Iranian, may also add to the difficulty. The status of Armenian as a Satem language as opposed to a Centum language with secondary assibilation rests on the evidence of a very few words.
The Centum languages show characteristic pure velars and labiovelars articulated at the back of the mouth in inherited Indo-European lexical items in which in other languages termed the Satem Languages affricate and fricative consonants articulated in the front of the mouth are found. The name Centum comes from the Latin word centum (pronounced [kentum]) < PIE *ḱm̥tóm, '100', English hund(red)- (with /h/ from earlier *k, see Grimm's law), Greek (he)katon, Welsh cant, Tocharian B kante. Labiovelars as single phonemes (for example, /kʷ/), as opposed to biphonemes (for example, /kw/) are attested in Greek (the Linear B q- series), Italic (Latin qu), Germanic (Gothic hwair ƕ and qairþra q) and Celtic (Ogham ceirt Q). In the Centum languages, the palatovelar consonants merged into the plain velars (*k, *g, *gʰ). The merger left the Centum Group without palatovelars.
The Centum languages preserve Proto-Indo-European labiovelars (*kʷ, *gʷ, *gʷʰ) or their historical reflexes as distinct from plain velars; for example, PIE *k : *kʷ > Latin c /k/ : qu /kʷ/, Greek κ /k/ : π /p/ (or τ /t/ before front vowels), Gothic /h/ : /hʷ/, etc. Remnants of labial elements from labiovelars in Balto-Slavic include Lithuanian ungurys "eel" < *angʷi- , Lithuanian dygus "pointy" < *dʰeigʷ-. Fewer examples of incomplete Satemization are also known from Indo-Iranian, such as Sanskrit guru "heavy" < *gʷer-, kulam "herd" < *kʷel-; kuru "make" < *kʷer- may be compared, but they arise only post-Rigvedic in attested texts.
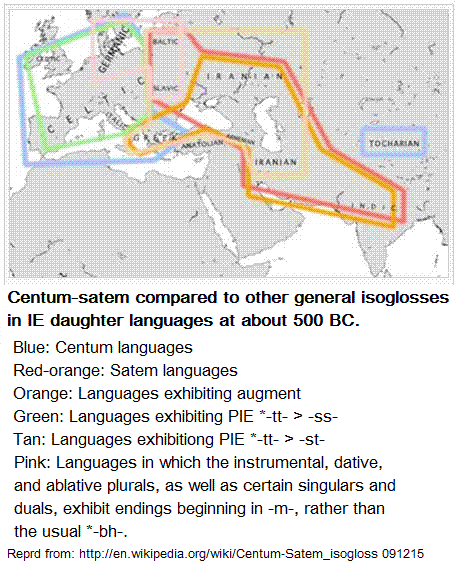
When von Bradke first published his views (1890) defining the Centum and Satem Languages, both major theories of language origination, the Tree model and the Wave model already existed. Bradke viewed his classification as "the oldest perceivable division" in Indo-European.[19] Each of these had further "divisions;" that is, Bradke was proposing a tree division, which he elucidated as "a division between eastern and western cultural provinces (Kulturkreises)."[24] The hypothesis came toward the end of Johannes Schmidt's career, innovator of the Wave model. He did not address it and it remained in place as the mainstream hypothesis even though cross-Kulturkreis similarities were noted. For example, referring to the "two sections", Peter Giles in 1901 noted "striking similarities" in languages across them, such as "Italic and Lettic."[25]
The proposed split was undermined by the discoveries of Hittite and Tocharian, which were Centum languages located within the hypothetical Satem range, Tocharian isolated on the Silk Route in the far east, divided from its closest cognates in Europe by thousands of miles of rugged terrain and hostile peoples.[3][26] This proposed first division based on a single isogloss was further weakened by continued research into additional Indo-European isoglosses, many of which seemed of equal or greater importance in the development of daughter languages. Philip Baldi explains:
"...an early dialect split of the type indicated by the centum-satem contrast should be expected to be reflected in other high-order dialect distinctions as well, a pattern which is not evident from an analysis of shared features among eastern and western languages."[26]
Colin Renfrew notes that the satem-centum distinction "is not in itself accorded much significance today"[3] as it is considered "too simplistic".[27] Tree models of the descent of PIE into the various daughter languages still exist but in the absence of historical data for the early stages of those languages the genetic models necessarily rely on comparative data; that is, the isogloss map. The Centum-Satem isogloss is just one of many that criss-cross the Indo-European landscape.[28] Similarly the rejection of Kossinna's Law matching archaeological cultures to language groups in strict correspondance opened a gap between specific tree models and any archaeological support that might be found in prehistory. Archaeology is still useful, as are tree models, but only in a limited way in contexts of preponderance of evidence; that is, the existence of specific cultures in the hypothetical origin area of satemization proves nothing whatever, not even that the sound change originated there. If an origin is to be postulated for that region, however, the archaeology adds that some sort of cultural unity resulting from a common way of life prevailed there.
Application of the wave model is equally difficult. Renfrew's statement of it supposes a Satem center from which a wave of satemization spread, but "the original, earlier Centum remains untouched in the periphery."[6] Centum may at least in many cases (but not Anatolian) have been earlier but it was not original; moreover, Centumization removed the palatovelars from the language, leaving none to satemize. It is necessary to suppose that in any given region Centumization competed with Satemization, which the mixed inventory of Balto-Slavic may support, but the Wave model in this statement of it appears equally as simplistic as the Tree model.
A compromise possibility is that PIE was neither Centum nor Satem, but satemization began in a central area and diffused outward from there. This view falls within the Wave model but begins from a different origin. Where satemization did not reach centumization took place either in different languages, or in a different lexical inventory of the same language, or not at all, allowing for the complexity of outcomes noted by the linguistic community. Winfred Lehmann presents this view based on the work of Antoine Meillet. Meillet had hypothesized a two-row tectal system, labiovelars and velars, but his velars were composed of two allophonic rows, pure velars used before back vowels and palatovelars before front. Lehmann says "Proper treatment of the subject involves consideration of the early Indo-European languages as members of a dialect continuum. In a central area, spirantization of the palatal allophones took place ...." [29]
• Brugmann, Karl (1886) (in German). Grundriss der Vergleichenden Grammatik der indogermanischen Sprachen. Erster Band. Strassburg: Karl J. Trübner.
• Brugmann, Karl; Delbrück, Berthold (1897-1916). Grundriss der vergleichenden grammatik der indogermanischen sprachen. Volume I Part 1 (2nd ed.). Strassburg: K.J. Trübner.
• Fortson, Benjamin W. (2010). Indo-European Language and Culture: An Introduction. Blackwell Textbooks in Linguistics (2nd ed.). Chichester, U.K.; Malden, MA: Wiley-Blackwell.
• Kortlandt, Frederik (1993). "General Linguistics & Indo-European Reconstruction" (PDF). Frederik Kortlandt. http://www.kortlandt.nl/publications/art130e.pdf. Retrieved 30 November 2009.
• Lehmann, Winfred Philipp (1993). Theoretical Bases of Indo-European Linguistics. Taylor & Francis Group.
• Lyovin, Anatole (1997). An introduction to the languages of the world. New York: Oxford University Press.
• Mallory, J.P.; Adams, D.Q., eds (1997). "Proto-Indo-European". Encyclopedia of Indo-European Culture. London, Chicago: Fitzroy Dearborn Publishers. ISBN 1-884964-98-2.
• Melchert, Craig (1987), "PIE velars in Luvian" (PDF), Studies in Memory of Warren Cowgill: pp. 182–204, http://www.linguistics.ucla.edu/people/Melchert/gscowgill.pdf, retrieved 28 November 2009 .
• Quiles, Carlos; López-Menchero, Fernando (2009). A Grammar of Modern Indo-European (Second ed.). Indo-European Language Assóciation.
• Remys, Edmund (2007). "General distinguishing features of various Indo-European languages and their relationship to Lithuanian" (in English). Indogermanische Forschungen (IF) 112: 244–276.
• Renfrew, Colin (1990). Archaelogy and language. Cambridge: Cambridge University Press. http://books.google.ca/books?id=R645AAAAIAAJ&pg=PA107.
• Schleicher, August (1871) (in German). Compendium der vergleichenden grammatik der indogermanischen sprachen. Weimar: Hermann Böhlau.
• Solta, G.R. (1965). "Palatalisierung und Labialisierung" (in German). Indogermanische Forschungen (IF) 70: 276–315.
• Szemerényi, Oswald J. L. (1990). Introduction to Indo-European Linguistics. Oxford [u.a.]: Oxford University Press.
• von Bradke, Peter (1890) (in German). Über Methode und Ergebnisse der arischen (indogermanischen) Alterthumswissenshaft. Giessen: J. Ricker'che Buchhandlung.
UKT: End of Wikipedia article. I have left out the references. Literature cited is given above.
Go back Centum-Satem-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Dravidian_languages 100308
 The
Dravidian
family of languages includes approximately 85 languages,[1]
spoken by around 200 million people. They are mainly spoken in
southern
India and parts of eastern and central
India as well as
in northeastern
Sri Lanka,
Pakistan, Nepal,
Bangladesh,
Afghanistan, Iran,
and overseas in other countries such as
Malaysia
and Singapore.
Among them
Tulu,
Kannada,
Telugu,
Tamil and
Malayalam are the members with the most speakers. There are also small
groups of Dravidian speaking
scheduled tribes, who live beyond the mainstream communities. It is often
speculated that Dravidian languages are native to
India.
Epigraphically the Dravidian languages have been attested since the 6th
century BC.
The
Dravidian
family of languages includes approximately 85 languages,[1]
spoken by around 200 million people. They are mainly spoken in
southern
India and parts of eastern and central
India as well as
in northeastern
Sri Lanka,
Pakistan, Nepal,
Bangladesh,
Afghanistan, Iran,
and overseas in other countries such as
Malaysia
and Singapore.
Among them
Tulu,
Kannada,
Telugu,
Tamil and
Malayalam are the members with the most speakers. There are also small
groups of Dravidian speaking
scheduled tribes, who live beyond the mainstream communities. It is often
speculated that Dravidian languages are native to
India.
Epigraphically the Dravidian languages have been attested since the 6th
century BC.
Linguist David McAlpin proposes that Dravidian and Elamite could be included in a broader Elamo-Dravidian language family, which may represent Proto-Dravidian itself. The yet to be deciphered Harappan language of the Indus Valley Civilization may share this same linguistic background.
...
The Dravidian languages have not been shown to be related to any other language family. Comparisons have been made not just with the other language families of the Subcontinent (Indo-European [IE], Austro-Asiatic, Tibeto-Burman, and Nihali), but with all typologically similar language families of the Old World. Dravidian is one of the primary linguistic groups in the proposed Nostratic proposal, which would link most languages in North Africa, Europe and Western Asia into a family with its origins in the Fertile Crescent sometime between the last Ice Age and the emergence of proto-Indo-European [PIE] 4-6 thousand years BCE. However, the general consensus is that such deep connections are not, or not yet, demonstrable.
On a less ambitious scale, several scholars have proposed linking Dravidian languages with the ancient Elamite language of what is now south-western Iran. However, despite decades of research, this Elamo-Dravidian language family has not been demonstrated to the satisfaction of many historical linguists.
Nonetheless, while there are no readily detectable genealogical connections, there are strong areal features linking Dravidian with the Indo-Aryan languages. Dravidian languages show extensive lexical (vocabulary) borrowing, but only a few traits of structural (either phonological or grammatical) borrowing, from Indo-Aryan, whereas the Indo-Aryan shows more structural features than lexical borrowings from the Dravidian languages. The Dravidian impact on the syntax of Indo-Aryan languages is considered far greater than the Indo-Aryan impact on Dravidian grammar. Some linguists explain this asymmetry by arguing that Middle Indo-Aryan languages were built on a Dravidian substratum.[24]
...
Dravidian languages are noted for the lack of distinction between aspirated and unaspirated stops. While some Dravidian languages (especially Malayalam, Kannada and Telugu) have accepted large numbers of loan words from Sanskrit and other Indo-European [IE] languages in addition to their already vast vocabulary, in which the orthography shows distinctions in voice and aspiration, the words are pronounced in Dravidian according to different rules of phonology and phonotactics: aspiration of plosives is generally absent, regardless of the spelling of the word. This is not a universal phenomenon and is generally avoided in formal or careful speech, especially when reciting.
For instance, Tamil, like Finnish, Korean, Ainu, and most indigenous Australian languages, does not distinguish between voiced and unvoiced stops. In fact, the Tamil alphabet lacks symbols for voiced and aspirated stops.
Dravidian languages are also characterized by a three-way distinction between dental, alveolar, and retroflex places of articulation as well as large numbers of liquids.
...
Dravidian and Sanskrit have influenced each other in various ways from very early times, hence it is an interesting field for linguistic research.
Well-known Indologist and linguist (Zvelebil 1975: pp50-51): "... the period of the high water mark of Tamil classical literature was one in which the two great Sanskrit epics were already completed, but the Sanskrit classical poetry was barely emerging with Aśvaghoṣa." More importantly he continues: "No stylistic feature or convention could have been borrowed by the Tamils (though of course there are borrowings of purāṇic stories" (emphasis added). Zvelebil remarks:"Though the dominance of Sanskrit was exaggerated in some Brahmanic circles of Tamilnadu, and Tamil was given unduly underestimated by a few Sanskrit-oriented scholars, the Tamil and Sanskrit cultures were not generally in rivalry".
However more recent research has shown that Sanskrit has been influenced in certain more fundamental ways than Dravidian languages have been by it: It is by way of phonology[26] and even more significantly here via grammatical constructs. This has been the case from the earliest language available (ca. 1200 B.C.) of Sanskrit: the Ṛg Vedic speech.
Basically, Dravidian languages show extensive lexical (vocabulary) borrowing, but only a few traits of structural (either phonological or grammatical) borrowing, from the Indo-Aryan tongues. On the other hand, Indo-Aryan shows rather large-scale structural borrowing from Dravidian, but relatively few loanwords.[27]
The Ṛg Vedic language has retroflex consonants even though it is well known that the Indo European family and the Indo-Iranian subfamily to which Sanskrit belongs lack retroflex consonants (ṭ/ḍ, ṇ) with about 88 words in the Ṛg Veda having unconditioned retroflexes (Kuiper 1991, Witzel 1999). Some sample words are: (Iṭanta, Kaṇva, śakaṭī, kevaṭa, puṇya, maṇḍūka) This is cited as a serious evidence of substrate influence from close contact of the Vedic speakers with speakers of a foreign language family rich in retroflex phonemes (Kuiper 1991, Witzel 1999). Obviously the Dravidian family would be a serious candidate here (ibid as well as Krishnamurti 2003: p36) since it is rich in retroflex phonemes reconstructible back to the Proto-Dravidian stage [See Subrahmanyam 1983:p40, Zvelebil 1990, Krishnamurti 2003].
A more serious influence on Vedic Sanskrit is the extensive grammatical influence attested by the usage of the quotative marker iti and the occurrence of gerunds of verbs, a grammatical feature not found even in the Avestan language, a sister language of the Vedic Sanskrit. As Krishnamurti states: "Besides, the Ṛg Veda has used the gerund, not found in Avestan, with the same grammatical function as in Dravidian, as a non-finite verb for 'incomplete' action. Ṛg Vedic language also attests the use of iti as a quotative clause complementizer. All these features are not a consequence of simple borrowing but they indicate substratum influence (Kuiper 1991: ch 2)".
The Brahui population of Balochistan has been taken by some as the linguistic equivalent of a relict population, perhaps indicating that Dravidian languages were formerly much more widespread and were supplanted by the incoming Indo-Aryan languages.[28]
Thomason & Kaufman (1988) state that there is strong evidence that Dravidian influenced Indic through "shift", that is, native Dravidian speakers learning and adopting Indic languages. Elst (1999) claims that the presence of the Brahui language, similarities between Elamite and Harappan script as well as similarities between Indo-Aryan and Dravidian indicate that these languages may have interacted prior to the spread of Indo-Aryans southwards and the resultant intermixing of languages. Erdosy (1995:18) states that the most plausible explanation for the presence of Dravidian structural features in Old Indo-Aryan is that the majority of early Old Indo-Aryan speakers had a Dravidian mother tongue which they gradually abandoned. Even though the innovative traits in Indic could be explained by multiple internal explanations, early Dravidian influence is the only explanation that can account for all of the innovations at once – it becomes a question of explanatory parsimony; moreover, early Dravidian influence accounts for the several of the innovative traits in Indic better than any internal explanation that has been proposed.[29]
The noted Indologist Zvelebil remarks[25]: "Several scholars have demonstrated that pre-Indo-Aryan and pre-Dravidian bilingualism in India provided conditions for the far-reaching influence of Dravidian on the Indo-Aryan tongues in the spheres of phonology (e.g., the retroflex consonants, made with the tongue curled upward toward the palate), syntax (e.g., the frequent use of gerunds, which are nonfinite verb forms of nominal character, as in “by the falling of the rain”), and vocabulary (a number of Dravidian loanwords apparently appearing in the Rigveda itself)"
UKT: Wikipedia article ends here: I've left out much in between which should be read.
Go back dravid-note-b
From: http://en.wikipedia.org/wiki/Shibboleth 100305
A shibboleth (pronounced /ˈʃɪbəlɛθ/[1] or /ˈʃɪbələθ/[2]) is any distinguishing practice which is indicative of one's social or regional origin. It usually refers to features of language, and particularly to a word whose pronunciation identifies its speaker as being a member or not a member of a particular group.
The term originates from the Hebrew word "shibbólet" (שִׁבֹּלֶת), which literally means the part of a plant containing grains, such as an ear of corn or a stalk of grain[3] or, in different contexts, "stream, torrent".[4][5] It derives from an account in the Hebrew Bible, in which pronunciation of this word was used to distinguish Ephraimites, whose dialect lacked a /ʃ/ sound (as in shoe), from Gileadites whose dialect did include such a sound.
UKT: Is it a coincidence or something else in the case of "grain-stream" in Hebrew and Burmese?
Burmese-Myanmar:
"grain" -{hsûn}/
{hsän} of
{praung:hsän}
"stream" -{sûn:} of
{sûn:hkyaung:}.
In the Book of Judges, chapter 12, after the inhabitants of Gilead inflicted a military defeat upon the tribe of Ephraim (around 1370–1070 BC), the surviving Ephraimites tried to cross the Jordan River back into their home territory and the Gileadites secured the river's fords to stop them. In order to identify and kill these refugees, the Gileadites put each refugee to a simple test:
Gilead then cut Ephraim off from the fords of the Jordan, and whenever Ephraimite fugitives said, 'Let me cross,' the men of Gilead would ask, 'Are you an Ephraimite?' If he said, 'No,' they then said, 'Very well, say "Shibboleth" (שיבולת).' If anyone said, "Sibboleth" (סיבולת), because he could not pronounce it, then they would seize him and kill him by the fords of the Jordan. Forty-two thousand Ephraimites fell on this occasion.
In numerous cases of conflict between groups speaking different languages or dialects, one side used shibboleths in a way similar to the above-mentioned Biblical use, i.e., to discover hiding members of the opposing group. Christians might have been familiar with the Biblical story and directly inspired by it, or might have independently invented the same method under similar circumstances. Modern researchers use the term "Shibboleth" for all such usages, whether or not the people involved were using it themselves.
Today, in the English language, a shibboleth also has a wider meaning, referring to any "in-crowd" word or phrase that can be used to distinguish members of a group from outsiders - even when not used by a hostile other group. The word is also sometimes used in a broader sense to mean jargon, the proper use of which identifies speakers as members of a particular group or subculture.
Shibboleths can also be customs or practices, such as male circumcision, or a signifier, such as a semiotic.
Cultural touchstones and shared experience can also be shibboleths of a sort. For example, people about the same age who are from the same nation tend to have the same memories of popular songs, television shows, and events from their formative years. One-hit wonders prove particularly effective. Much the same is true of alumni of a particular school, veterans of military service, and other groups. Discussing such memories is a common way of bonding. In-jokes can be a similar type of shared-experience shibboleth.
Yet another more pejorative usage involves underlining the fact that the original meaning of a symbol has in effect been lost and that the symbol now serves merely to identify allegiance. For example, if a group repressed the denigration of one of their cultural symbols when the symbol originally was meant to represent freedom of speech, then the symbol could be described as being nothing more than a 'shibboleth'.
 Shibboleths
have been used by different subcultures throughout the world at different times.
Regional differences, level of expertise and computer coding techniques are
several forms that shibboleths have taken. For example, during the
Battle of the Bulge, American soldiers used knowledge
of baseball to determine if others were fellow Americans
or if they were German infiltrators in American uniform.
The Dutch famously used the name of the port town
Scheveningen as a shibboleth to tell Germans from the Dutch (the Dutch
pronounce the S separately from the ch). Some shibboleths are
jokes.
Shibboleths
have been used by different subcultures throughout the world at different times.
Regional differences, level of expertise and computer coding techniques are
several forms that shibboleths have taken. For example, during the
Battle of the Bulge, American soldiers used knowledge
of baseball to determine if others were fellow Americans
or if they were German infiltrators in American uniform.
The Dutch famously used the name of the port town
Scheveningen as a shibboleth to tell Germans from the Dutch (the Dutch
pronounce the S separately from the ch). Some shibboleths are
jokes.
During World War II, some United States soldiers in the Pacific theater used the word " lollapalooza" as a shibboleth to verbally test people who were hiding and unidentified, on the premise that Japanese people often pronounce the letter L as R, and that the word is an American colloquialism that even a foreign person fairly well-versed in American English would probably mispronounce and/or be unfamiliar with. [6] In George Stimpson's A Book about a Thousand Things, the author notes that, in the war, Japanese spies would often approach checkpoints posing as American or Filipino military personnel. A shibboleth such as "lollapalooza" would be used by the sentry, who, if the first two syllables come back as rorra, would "open fire without waiting to hear the remainder". [7]
Prior to the Guldensporenslag, the Flemish slaughtered every Frenchman they could find in the city of Bruges. They are said to have identified Frenchmen based on their inability to pronounce the phrase "Scilt ende Vriend" ("Shield and Friend"), or possibly "'s Guilden vriend" ("Friend of the Guilds").
Bûter, brea, en griene tsiis; wa't dat net sizze kin, is gjin oprjochte Fries means "Butter, rye bread and green cheese, who cannot say that is not a genuine Frisian" was used by the Frisian Pier Gerlofs Donia during a Frisian rebellion war (1515-1523). Ships whose crew could not pronounce this properly were usually plundered and soldiers who could not were beheaded by Donia himself.[8]
Go back shibboleth-note-b
End of TIL file